[논문] Neural Machine Translation of Rare Words with Subword Units (2016)
Neural Machine Translation of Rare Words with Subword Units (2016)
출처: https://arxiv.org/pdf/1508.07909.pdf
Abstract
Neural machine translation (NMT) 모델은 일반적으로 고정된 단어에서 작동하지만, 번역에서는 open-vocabulary 문제를 가지고 있습니다. 이전의 작업들에선 사전으로 돌아가 어휘 밖의 단어를 번역하기 위해 노력하고 있습니다. 이 논문에서는 rare하고 unknown한 단어를 subword 단위의 시퀀스로 인코딩하여 NMT 모델을 open-vocabulary translation이 가능하도록 만드는 더 간단하고 효과적인 접근 방식을 소개합니다. 이는 다양한 단어 클래스가 단어보다 작은 단위를 통해 번역될 수 있다는 직관에 기반합니다.
여기선 간단한 n-gram 모델과 Byte Pair Encoding (BPE)을 기반으로 한 분할을 포함하여 다양한 단어 분할 기술의 적절성에 대해 논의하고 서브워드 모델이 경험적으로 성능이 향상됨을 보여줍니다.
1 Introduction
Neural machine translation (NMT)는 최근에 엄청난 성능을 보여주고 있지만, 여전히 open-vocabulary problem(사전에 등록되지 않는 단어가 나오는 현상)이 있습니다.
여기서는 neural network가 subword 표현을 통해 합성어와 transliteration을 학습할 수 있다는 것을 보여줍니다.
이 논문에서의 주된 두가지 contributions:
- neural machine translation (NMT)가 subword를 통해 인코딩 가능하다는 것을 보여줍니다.
- byte pair encoding (BPE)를 적용
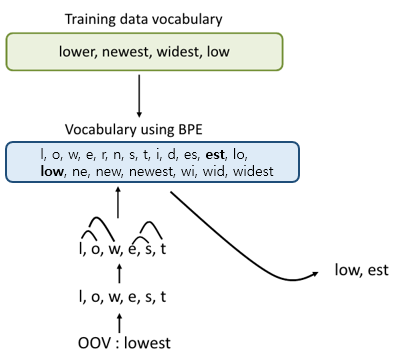
3.2 Byte Pair Encoding (BPE)
Byte Pair Encoding (BPE)는 시퀀스에서 가장 빈도수가 높은 바이트 쌍을 하나의 데이터 혹은 사용되지 않는 바이트로 바꿔가는 간단한 데이터 압축 기술입니다. 여기서는 이 알고리즘을 단어 분할을 하는데 적용합니다. 따라서, 바이트가 아니라 문자나 문자 스퀀스를 합칩니다.
먼저, symbol vocabulary를 chracter vocabulary로 초기화하고, 각 단어를 일련의 문자와 단어의 끝을 의미하는 “.”으로 나타내어 번역 후에도 원래의 tokenization을 복원할 수 있습니다.
여기서는 모든 pair을 반복적으로 계산하고 가장 빈도수가 높은 pair(‘A’, ‘B’)가 나타날 때마다 새로운 기호 ‘AB’로 교체합니다. 각 병합 작업은 문자 n-gram을 나타내는 새 symbol을 생성합니다. 빈도수가 높은 문자 n-gram(혹은 전체 단어)은 결국 하나의 symbol로 병합되므로 BPE에는 shortlist가 필요하지 않습니다. 마지막 symbol 사이즈는 초기의 단어 사이즈와 같아집니다.

- 동작 방식
6 Conclusion
이 논문의 주요 contribution은 neural machine translation system이 subword 단위의 시퀀스로 rare하고 unknown한 단어를 표현함으로써 open-vocabulary 번역이 가능하다는 것을 보여주었다는 것입니다. 이것은 back-off translation model을 사용하는 것보다 더 간단하고 효과적입니다.
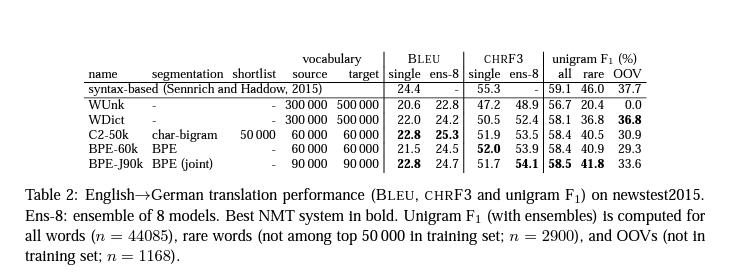
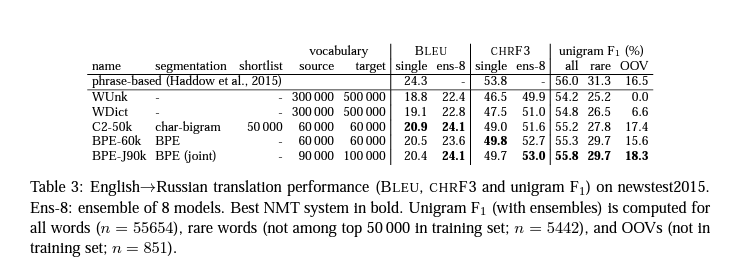
가변 길이 하위 단어 단위의 간결한 기호 어휘로 열린 어휘를 인코딩할 수 있는 단어 분할을 위한 바이트 쌍 인코딩의 변형을 소개합니다. 그리고 open vocabulary의 인코딩을 subword로 표현 가능하게 하는 Byte Pair Encoding (BPE)의 변형을 소개합니다. 그리고 여기서는 BPE 분할과 단순한 bi-gram 분할의 비교를 통해 성능의 향상을 보여줍니다.
댓글남기기