TabNet으로 하는 Classification: Deep Dive
[공지사항] “출처: https://syslog.ravelin.com/classification-with-tabnet-deep-dive-49a0dcc8f7e8”
Classification with TabNet: Deep Dive

여기서는 해석 가능하고 테이블 형식 데이터와 잘 작동하도록 설계된 TabNet (Arik & Pfister(2019))이라는 neural architecture에 대해 자세히 알아볼 것입니다. 핵심 building block과 그 이면의 아이디어를 설명한 후, TensorFlow에서 구현하는 방법과 사기 탐지 데이터 세트에 적용하는 방법을 알 수 있습니다. 대부분의 코드는 여기에서 가져왔습니다.
TabNet
TabNet은 Sequential Attention의 아이디어를 사용하여 decision tree의 동작을 모방합니다. 간단히 말해서 각 단계에서 두 가지 주요 작업을 적용하는 multi-step neural network로 생각할 수 있습니다:
-
Attentive Transformer는 다음 단계에서 처리할 가장 중요한 feature를 선택합니다.
-
Feature Transformer는 feature를 보다 유용한 표현으로 처리합니다.
Feature Transformer의 output은 나중에 예측에 사용됩니다. Attentive와 Feature Transformer를 모두 사용하여 TabNet은 tree-based model의 의사 결정 프로세스를 시뮬레이션할 수 있습니다.
모델은 해석 가능성과 학습을 향상시키는 task에 가장 유용한 feature를 선택하고 처리할 수 있습니다.
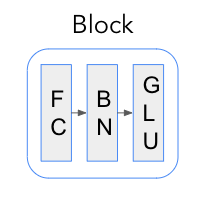
Attentive와 Feature Transformer의 key building block은 Feature Blocks입니다. 이제 이들을 살펴봅시다.
Feature Blocks
Feature Block은 순차적으로 적용된 FC (Fully-Connected)(or Dense) layer와 Batch Normalization (BN)으로 구성됩니다. 또한, Feature Transformers의 경우 output이 GLU activation layer를 통과합니다.
GLU(sigmoid gate와 반대)의 주요 기능은 hidden unit이 모델에 더 깊이 전달되도록 하고, gradient exploding이나 vanishing을 방지하는 것입니다.
def glu(x, n_units=None):
"""Generalized linear unit nonlinear activation."""
return x[:, :n_units] * tf.nn.sigmoid(x[:, n_units:])
또한, 원본 논문은 training 중 convergence speed를 향상시키기 위해 Ghost Batch Normalization을 사용합니다. 관심이 있는 경우, 여기에서 Tensorflow implementation을 찾을 수 있지만, 이 tutorial에서는 default Batch Normalization layer를 사용합니다.
class FeatureBlock(tf.keras.Model):
"""
Implementation of a FL->BN->GLU block
"""
def __init__(
self,
feature_dim,
apply_glu = True,
bn_momentum = 0.9,
fc = None,
epsilon = 1e-5,
):
super(FeatureBlock, self).__init__()
self.apply_gpu = apply_glu
self.feature_dim = feature_dim
units = feature_dim * 2 if apply_glu else feature_dim # desired dimension gets multiplied by 2
# because GLU activation halves it
self.fc = tf.keras.layers.Dense(units, use_bias=False) if fc is None else fc # shared layers can get re-used
self.bn = tf.keras.layers.BatchNormalization(momentum=bn_momentum, epsilon=epsilon)
def call(self, x, training = None):
x = self.fc(x) # inputs passes through the FC layer
x = self.bn(x, training=training) # FC layer output gets passed through the BN
if self.apply_gpu:
return glu(x, self.feature_dim) # GLU activation applied to BN output
return x
Feature Transformers
FeatureTransformer(FT)는 기본적으로 순차적으로 적용되는 feature blocks의 collection입니다. 논문에서 하나의 FeatureTransformer는 2개의 shared blocks(즉, weight은 steps에서 재사용)과 2개의 step dependent blocks으로 구성됩니다. shared weights는 모델의 parameters를 줄이고 더 나은 일반화로 이어집니다.

이전 section의 Feature Block 구현을 고려하여, Feature Transformer를 구축하는 방법은 다음과 같습니다.
class FeatureTransformer(tf.keras.Model):
def __init__(
self,
feature_dim,
fcs = [],
n_total = 4,
n_shared = 2,
bn_momentum = 0.9,
):
super(FeatureTransformer, self).__init__()
self.n_total, self.n_shared = n_total, n_shared
kwrgs = {
"feature_dim": feature_dim,
"bn_momentum": bn_momentum,
}
# build blocks
self.blocks = []
for n in range(n_total):
# some shared blocks
if fcs and n < len(fcs):
self.blocks.append(FeatureBlock(**kwrgs, fc=fcs[n])) # Building shared blocks by providing FC layers
# build new blocks
else:
self.blocks.append(FeatureBlock(**kwrgs)) # Step dependent blocks without the shared FC layers
def call(self, x, training = None):
# input passes through the first block
x = self.blocks[0](x, training=training)
# for the remaining blocks
for n in range(1, self.n_total):
# output from previous block gets multiplied by sqrt(0.5) and output of this block gets added
x = x * tf.sqrt(0.5) + self.blocks[n](x, training=training)
return x
@property
def shared_fcs(self):
return [self.blocks[i].fc for i in range(self.n_shared)]
Attentive Transformer
AT(Attentive Transformer)는 각 step에서 feature selection을 담당합니다. feture selection은 prior scale을 고려하면서 (GLU 대신) sparsemax activation를 적용하여 수행됩니다. prior scale를 사용하면 모델에서 feature를 선택할 수 있는 빈도를 제어할 수 있으며, 이전 단계에서 사용된 빈도에 따라 제어할 수 있습니다.
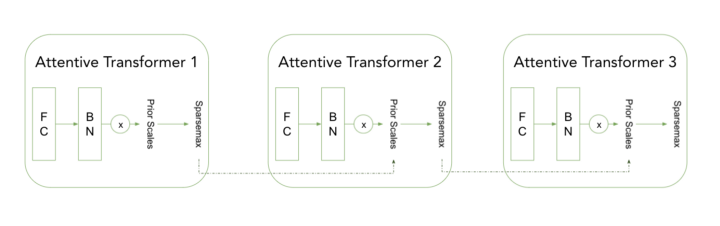
이전 Attention Transformer는 이전 step에서 사용된 feature에 대한 정보를 따라 prior scale로 전달됩니다. Feature Transformer와 유사하게, Attentive Transformer는 나중에 더 큰 아키텍처에 통합될 TensorFlow 모델로 구현될 수 있습니다.
class AttentiveTransformer(tf.keras.Model):
def __init__(self, feature_dim):
super(AttentiveTransformer, self).__init__()
self.block = FeatureBlock(
feature_dim,
apply_glu=False, # sparsemax instead of glu
)
def call(self, x, prior_scales, training=None):
# Pass input trhough a FC-BN block
x = self.block(x, training=training)
# Pass the output through sparsemax activation
return sparsemax(x * prior_scales)
Feature와 Attentive Transformer block은 parameter가 상당히 무거울 수 있으므로 TabNet은 몇 가지 메커니즘을 사용하여 복잡성을 제어하고 overfitting을 방지합니다.
Regularisation
Prior Scales Calculation
Prior scales(P)를 사용하면 모델에서 feature를 선택할 수 있는 빈도를 제어할 수 있습니다. prior scale(P)은 이전 Attentive Transformer activation 및 relaxation factor($γ$) parameter를 사용하여 계산됩니다. 다음은 논문에 제시된 공식입니다.
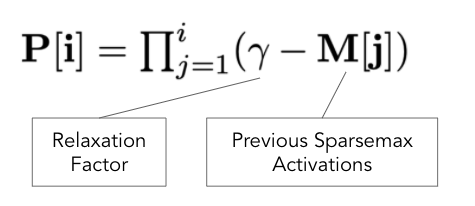
이 방정식은 prior scales가 어떻게 업데이트되는지 보여줍니다. 업데이트는 현재 step $i$까지의 모든 단계에 대한 product입니다. 직관적으로, 이전 steo에서 feature가 사용된 경우, 모델은 overfitting을 줄이기 위해 나머지 feature에 더 많은 주의를 기울입니다.
예를 들어, $γ$=1일 때 multiplicative activations(예: 0.9)가 있는 feature는 작은 prior scales(1–0.9=0.1)를 갖습니다.
Sparsity regularisation
loss에 대한 sparsity regularization은 attention mask가 sparse하도록 장려하기 위해 사용됩니다. hyperparameter $λ$에 의해 스케일링된 entropy of activations는 전체 모델 loss에 추가됩니다.
def sparse_loss(at_mask):
loss = tf.reduce_mean(
tf.reduce_sum(tf.multiply(-at_mask, tf.math.log(at_mask + 1e-15)),
axis=1)
)
return loss
not_sparse_mask = np.array([[0.4, 0.5, 0.05, 0.05],
[0.2, 0.2, 0.5, 0.1]])
sparse_mask = np.array([[0.0, 0.0, 0.7, 0.3],
[0.0, 0.0, 1, 0.0]])
print('Loss for non-sparse attention mask:', sparse_loss(not_sparse_mask).numpy())
print('Loss for sparse attention mask:', sparse_loss(sparse_mask).numpy())
# Loss for non-sparse attention mask: 1.1166351874690217
# Loss for sparse attention mask: 0.3054321510274452
다음으로 이러한 구성 요소를 사용하여 TabNet 모델을 구축하는 방법을 알아보겠습니다.
TabNet Architecture
Putting It All Together
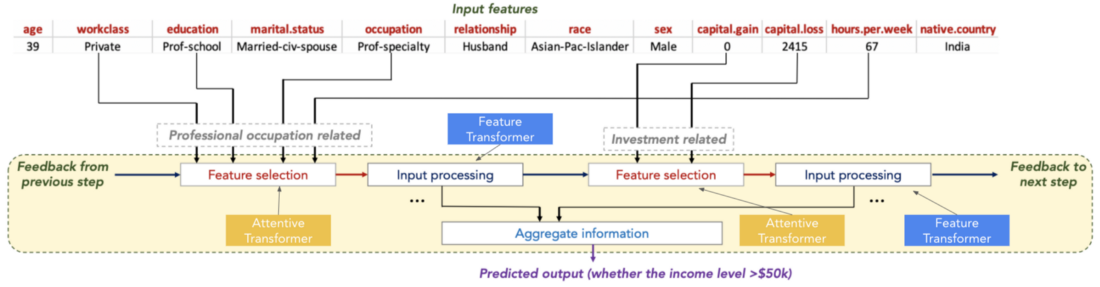
TabNet의 기본 아이디어는 Feature 및 Attentive Transformers 구성 요소가 순차적으로 적용되어 모델이 decision tree를 만드는 과정을 모방할 수 있다는 것입니다. Attentive Transformer는 feature selection을 수행하고 Feature Transformer는 모델이 데이터의 복잡한 패턴을 학습할 수 있도록 하는 transformations를 수행합니다. 아래에서 2-step TabNet 모델에 대한 data flow를 요약한 다이어그램을 볼 수 있습니다.
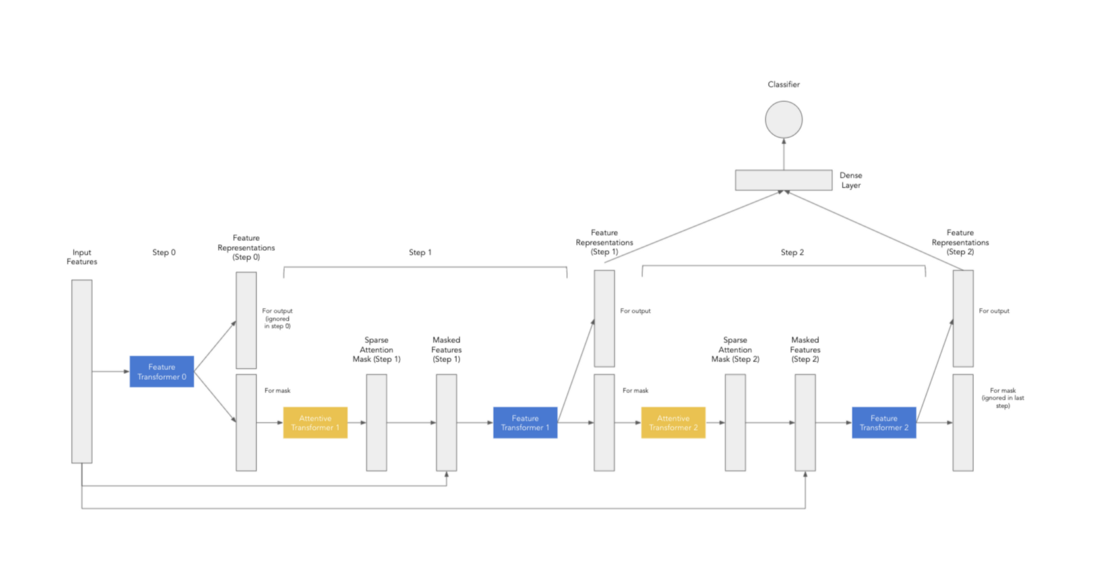
우선 초기 input features를 Feature Transformer를 통해 전달하여 초기 feature representations를 얻습니다. 이 Feature Transformer의 output은 다음 단계로 전달할 features의 subset을 선택하는 Attentive Transformer에 대한 input으로 사용됩니다. 이 프로세스는 필요한 단계 수만큼 반복됩니다. (이 code snippet에서 위에 정의된 클래스를 사용하여 TensorFlow 구현을 볼 수 있습니다)
모델은 각 decision step의 Feature Transformer output을 사용하여 최종 예측을 생성합니다. 또한 각 step에서 attention mask를 집계하여 예측에 사용된 feature를 이해할 수 있습니다. 이러한 mask는 global importances뿐만 아니라 local feature importances를 얻는 데 사용할 수 있습니다.
이제 실습을 시작해봅시다.
실습: Fraud Detectioin
imports
from tqdm import tqdm
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from category_encoders.woe import WOEEncoder
from sklearn.compose import ColumnTransformer
from sklearn.metrics import average_precision_score, roc_auc_score, confusion_matrix
from tensorflow_addons.activations import sparsemax
from scipy.special import softmax
import matplotlib.pyplot as plt
import seaborn as sns
Data
(데이터 경로)
데이터가 2개로 나뉘어 있기 때문에, merge가 필요합니다
train_transactions = pd.read_csv('train_transaction.csv')
train_identity = pd.read_csv('train_identity.csv')
# merge two datasets
train = pd.merge(train_transactions, train_identity, on='TransactionID', how='left')
train['isFraud'].value_counts(normalize=True)
0 0.98441
1 0.01559
Name: isFraud, dtype: float64
test_transactions = pd.read_csv('test_transaction.csv')
test_identity = pd.read_csv('test_identity.csv')
# merge two datasets
test = pd.merge(test_transactions, test_identity, on='TransactionID', how='left')
test.columns = [c.replace('-', '_') for c in test.columns]
Feature Engineering
feature engineering은 fraud detection 영역에서 가장 중요한 단계입니다. 그러나 이 프로젝트의 주요 목표가 아니므로 이 단계를 건너뛰고 독자에게 맡기겠습니다.
# Make an hour feature from datetime stamp
def make_hour_feature(f):
#Creates an hour of the day feature, encoded as 0-23.
hours = f / (3600)
encoded_hours = np.floor(hours) % 24
return encoded_hours
train['hour'] = make_hour_feature(train['TransactionDT'])
test['hour'] = make_hour_feature(test['TransactionDT'])
Data Cleaning
-
missing values가 많은 칼럼 제거
-
median 값을 missing values에 채워넣기
-
categorical 칼럼의 missing values에 “missing”이란 값으로 채워 넣기
cat_features = ['ProductCD', 'card1', 'card2', 'card3', 'card4', 'card5', 'card6',
'addr1', 'addr2', 'P_emaildomain', 'R_emaildomain', 'M1',
'M2', 'M3', 'M4', 'M5', 'M6', 'M7', 'M8', 'M9', 'DeviceType', 'DeviceInfo',
'id_12', 'id_13', 'id_14', 'id_15', 'id_16', 'id_17', 'id_18', 'id_19', 'id_20',
'id_21', 'id_22', 'id_23', 'id_24', 'id_25', 'id_26', 'id_27', 'id_28', 'id_29', 'id_30',
'id_31', 'id_32', 'id_33', 'id_34', 'id_35', 'id_36', 'id_37', 'id_38']
exclude = ['TransactionID', 'TransactionDT', 'isFraud']
num_features = [f for f in train.columns if (f not in cat_features) & (f not in exclude)]
# 결측치 90% 이상 칼럼 제거
col_na = train.isnull().sum()
to_drop = col_na[(col_na / train.shape[0]) > 0.9].index
use_cols = [f for f in train.columns if f not in to_drop]
cat_features = [f for f in cat_features if f not in to_drop]
num_features = [f for f in num_features if f not in to_drop]
train[cat_features] = train[cat_features].astype(str)
train[num_features] = train[num_features].astype(np.float)
train = train[use_cols]
test[cat_features] = test[cat_features].astype(str)
test[num_features] = test[num_features].astype(np.float)
test = test[[f for f in use_cols if f != 'isFraud']]
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:20: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:24: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
from sklearn.impute import SimpleImputer
# median 값 채워 넣기
train[num_features] = SimpleImputer(strategy="median").fit_transform(train[num_features])
train[cat_features] = train[cat_features].replace("nan", "missing")
train.isnull().sum().sum()
0
test[num_features] = SimpleImputer(strategy="median").fit_transform(test[num_features])
test[cat_features] = test[cat_features].replace("nan", "missing")
test.isna().sum().sum()
0
train.shape
(898, 423)
Train/Val Split
testing은 미래 시점에 수행되므로 validationi split은 datetime 칼럼을 사용하여 수행합니다.
train_split = train["TransactionDT"] <= np.quantile(train["TransactionDT"], 0.9)
train_X = train.loc[train_split.values, num_features + cat_features]
train_y = train.loc[train_split.values, "isFraud"]
val_X = train.loc[~train_split.values, num_features + cat_features]
val_y = train.loc[~train_split.values, "isFraud"]
print(len(train_X), 'train examples')
print(len(val_X), 'validation examples')
808 train examples
90 validation examples
Pre-processing
neural network는 숫자 데이터만 처리할 수 있으므로 input을 전처리해야 합니다. 아래 코드는 매우 단순화한 전처리 파이프라인이며 categoy embeddings와 같은 보다 정교한 방법 바꿀 수 있습니다.
-
numeric features 스케일링
-
categorical features 인코딩
scaler = StandardScaler()
woe = WOEEncoder()
column_trans = ColumnTransformer(
[("scaler", scaler, num_features),
("woe", woe, cat_features)], remainder="passthrough", n_jobs=-1
)
train_X_transformed = column_trans.fit_transform(train_X, train_y)
val_X_transformed = column_trans.transform(val_X)
test_X_transformed = column_trans.transform(test[num_features + cat_features])
print(train_X_transformed.shape, val_X_transformed.shape, test_X_transformed.shape)
(808, 420) (90, 420) (1834, 420)
train_X_transformed = pd.DataFrame(train_X_transformed, columns=[num_features + cat_features])
val_X_transformed = pd.DataFrame(val_X_transformed, columns=[num_features + cat_features])
test_X_trinsformed = pd.DataFrame(test_X_transformed, columns=[num_features + cat_features])
TF Data
training과 inference를 더 빠르게 하려면 데이터를 TF Data object로 변환해야 합니다.
def prepare_tf_dataset(X, batch_size, y=None, shuffle=False, drop_remainder=False):
size_of_dataset = len(X)
if y is not None:
y = tf.one_hot(y.astype(int), 2)
ds = tf.data.Dataset.from_tensor_slices((np.array(X.astype(np.float32)), y))
else:
ds = tf.data.Dataset.from_tensor_slices(np.array(X.astype(np.float32)))
if shuffle:
ds = ds.shuffle(buffer_size=size_of_dataset)
ds = ds.batch(batch_size, drop_remainder=drop_remainder)
autotune = tf.data.experimental.AUTOTUNE
ds = ds.prefetch(autotune)
return ds
train_ds = prepare_tf_dataset(train_X_transformed, 16384, train_y)
val_ds = prepare_tf_dataset(val_X_transformed, 16384, val_y)
test_ds = prepare_tf_dataset(test_X_transformed, 16384)
Model
TabNet
위에서 언급한 클래스를 모두 정의
def glu(x, n_units=None):
"""Generalized linear unit nonlinear activation."""
return x[:, :n_units] * tf.nn.sigmoid(x[:, n_units:])
class FeatureBlock(tf.keras.Model):
"""
Implementation of a FL->BN->GLU block
"""
def __init__(
self,
feature_dim,
apply_glu = True,
bn_momentum = 0.9,
fc = None,
epsilon = 1e-5,
):
super(FeatureBlock, self).__init__()
self.apply_gpu = apply_glu
self.feature_dim = feature_dim
units = feature_dim * 2 if apply_glu else feature_dim # desired dimension gets multiplied by 2
# because GLU activation halves it
self.fc = tf.keras.layers.Dense(units, use_bias=False) if fc is None else fc # shared layers can get re-used
self.bn = tf.keras.layers.BatchNormalization(momentum=bn_momentum, epsilon=epsilon)
def call(self, x, training = None):
x = self.fc(x) # inputs passes through the FC layer
x = self.bn(x, training=training) # FC layer output gets passed through the BN
if self.apply_gpu:
return glu(x, self.feature_dim) # GLU activation applied to BN output
return x
class FeatureTransformer(tf.keras.Model):
def __init__(
self,
feature_dim,
fcs = [],
n_total = 4,
n_shared = 2,
bn_momentum = 0.9,
):
super(FeatureTransformer, self).__init__()
self.n_total, self.n_shared = n_total, n_shared
kwrgs = {
"feature_dim": feature_dim,
"bn_momentum": bn_momentum,
}
# build blocks
self.blocks = []
for n in range(n_total):
# some shared blocks
if fcs and n < len(fcs):
self.blocks.append(FeatureBlock(**kwrgs, fc=fcs[n])) # Building shared blocks by providing FC layers
# build new blocks
else:
self.blocks.append(FeatureBlock(**kwrgs)) # Step dependent blocks without the shared FC layers
def call(self, x, training = None):
# input passes through the first block
x = self.blocks[0](x, training=training)
# for the remaining blocks
for n in range(1, self.n_total):
# output from previous block gets multiplied by sqrt(0.5) and output of this block gets added
x = x * tf.sqrt(0.5) + self.blocks[n](x, training=training)
return x
@property
def shared_fcs(self):
return [self.blocks[i].fc for i in range(self.n_shared)]
class AttentiveTransformer(tf.keras.Model):
def __init__(self, feature_dim):
super(AttentiveTransformer, self).__init__()
self.block = FeatureBlock(
feature_dim,
apply_glu=False,
)
def call(self, x, prior_scales, training=None):
x = self.block(x, training=training)
return sparsemax(x * prior_scales)
class TabNet(tf.keras.Model):
def __init__(
self,
num_features,
feature_dim,
output_dim,
n_step = 2,
n_total = 4,
n_shared = 2,
relaxation_factor = 1.5,
bn_epsilon = 1e-5,
bn_momentum = 0.7,
sparsity_coefficient = 1e-5
):
super(TabNet, self).__init__()
self.output_dim, self.num_features = output_dim, num_features
self.n_step, self.relaxation_factor = n_step, relaxation_factor
self.sparsity_coefficient = sparsity_coefficient
self.bn = tf.keras.layers.BatchNormalization(
momentum=bn_momentum, epsilon=bn_epsilon
)
kargs = {
"feature_dim": feature_dim + output_dim,
"n_total": n_total,
"n_shared": n_shared,
"bn_momentum": bn_momentum
}
# first feature transformer block is built first to get the shared blocks
self.feature_transforms = [FeatureTransformer(**kargs)]
self.attentive_transforms = []
# each step consists out of FT and AT
for i in range(n_step):
self.feature_transforms.append(
FeatureTransformer(**kargs, fcs=self.feature_transforms[0].shared_fcs)
)
self.attentive_transforms.append(
AttentiveTransformer(num_features)
)
# Final output layer
self.head = tf.keras.layers.Dense(2, activation="softmax", use_bias=False)
def call(self, features, training = None):
bs = tf.shape(features)[0] # get batch shape
out_agg = tf.zeros((bs, self.output_dim)) # empty array with outputs to fill
prior_scales = tf.ones((bs, self.num_features)) # prior scales initialised as 1s
importance = tf.zeros([bs, self.num_features]) # importances
masks = []
features = self.bn(features, training=training) # Batch Normalisation
masked_features = features
total_entropy = 0.0
for step_i in range(self.n_step + 1):
# (masked) features go through the FT
x = self.feature_transforms[step_i](
masked_features, training=training
)
# first FT is not used to generate output
if step_i > 0:
# first half of the FT output goes towards the decision
out = tf.keras.activations.relu(x[:, : self.output_dim])
out_agg += out
scale_agg = tf.reduce_sum(out, axis=1, keepdims=True) / (self.n_step - 1)
importance += mask_values * scale_agg
# no need to build the features mask for the last step
if step_i < self.n_step:
# second half of the FT output goes as input to the AT
x_for_mask = x[:, self.output_dim :]
# apply AT with prior scales
mask_values = self.attentive_transforms[step_i](
x_for_mask, prior_scales, training=training
)
# recalculate the prior scales
prior_scales *= self.relaxation_factor - mask_values
# multiply the second half of the FT output by the attention mask to enforce sparsity
masked_features = tf.multiply(mask_values, features)
# entropy is used to penalize the amount of sparsity in feature selection
total_entropy += tf.reduce_mean(
tf.reduce_sum(
tf.multiply(-mask_values, tf.math.log(mask_values + 1e-15)),
axis=1,
)
)
# append mask values for later explainability
masks.append(tf.expand_dims(tf.expand_dims(mask_values, 0), 3))
#Per step selection masks
self.selection_masks = masks
# Final output
final_output = self.head(out)
# Add sparsity loss
loss = total_entropy / (self.n_step-1)
self.add_loss(self.sparsity_coefficient * loss)
return final_output, importance
HP Tuning
메모리가 부족하면 pass
-
Feature Dimension - between 32 and 512
-
Number of steps - from 2 to 9
-
Relaxation factor - from 1 to 3
-
Sparsity Coefficiet - from 0 to 0.1
-
Batch Momentum - from 0.9 to 0.9999
-
Class weight - from 1 to 10
import optuna
from optuna import Trial, visualization
def Objective(trial):
feature_dim = trial.suggest_categorical("feature_dim", [32, 64, 128, 256, 512])
n_step = trial.suggest_int("n_step", 2, 9, step=1)
n_shared = trial.suggest_int("n_shared", 0, 4, step=1)
relaxation_factor = trial.suggest_float("relaxation_factor", 1., 3., step=0.1)
sparsity_coefficient = trial.suggest_float("sparsity_coefficient", 0.00000001, 0.1, log=True)
bn_momentum = trial.suggest_float("bn_momentum", 0.9, 0.9999)
tabnet_params = dict(num_features=train_X_transformed.shape[1],
output_dim=feature_dim,
feature_dim=feature_dim,
n_step=n_step,
relaxation_factor=relaxation_factor,
sparsity_coefficient=sparsity_coefficient,
n_shared = n_shared,
bn_momentum = bn_momentum)
cbs = [tf.keras.callbacks.EarlyStopping(
monitor="val_loss", patience=5, restore_best_weights=True
)]
tn = TabNet(**tabnet_params)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001, clipnorm=10)
loss = [tf.keras.losses.CategoricalCrossentropy(from_logits=False)]
tn.compile(optimizer, loss=loss)
tn.fit(train_ds, epochs=100, validation_data=val_ds, callbacks=cbs, verbose=1)
val_preds, _ = tn.predict(val_ds)
pr_auc = average_precision_score(val_y, val_preds[:,1])
return pr_auc
study = optuna.create_study(direction="maximize", study_name='TabNet optimization')
study.optimize(Objective, n_jobs=-1, n_trials=100, gc_after_trial=True, show_progress_bar=False)
1/1 [==============================] - 1s 1s/step
[32m[I 2022-10-28 04:39:39,946][0m Trial 99 finished with value: 0.037037037037037035 and parameters: {'feature_dim': 512, 'n_step': 2, 'n_shared': 3, 'relaxation_factor': 1.6, 'sparsity_coefficient': 4.914270468796725e-05, 'bn_momentum': 0.9339691060033563}. Best is trial 9 with value: 1.0.[0m
tabnet = TabNet(num_features=train_X_transformed.shape[1],
output_dim=128,
feature_dim=512,
n_step=2,
relaxation_factor=1.6,
sparsity_coefficient=4.914270468796725e-05,
n_shared=3,
bn_momentum=0.9339691060033563)
cbs = [tf.keras.callbacks.EarlyStopping(
monitor="val_loss", patience=30, restore_best_weights=True
)]
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001, clipnorm=10)
loss = [tf.keras.losses.CategoricalCrossentropy(from_logits=False)]
tabnet.compile(optimizer, loss=loss)
tabnet.fit(train_ds, epochs=1000, validation_data=val_ds, callbacks=cbs,
verbose=1, class_weight={0: 1, 1: 10})
Epoch 1/1000
1/1 [==============================] - 6s 6s/step - loss: 0.8348 - output_1_loss: 0.8348 - val_loss: 0.6883 - val_output_1_loss: 0.6883
Epoch 2/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.7702 - output_1_loss: 0.7702 - val_loss: 0.6806 - val_output_1_loss: 0.6806
Epoch 3/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.7298 - output_1_loss: 0.7298 - val_loss: 0.6748 - val_output_1_loss: 0.6748
Epoch 4/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.6864 - output_1_loss: 0.6864 - val_loss: 0.6684 - val_output_1_loss: 0.6684
Epoch 5/1000
1/1 [==============================] - 0s 66ms/step - loss: 0.5354 - output_1_loss: 0.5354 - val_loss: 0.6590 - val_output_1_loss: 0.6590
Epoch 6/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.4201 - output_1_loss: 0.4201 - val_loss: 0.6458 - val_output_1_loss: 0.6458
Epoch 7/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.3515 - output_1_loss: 0.3515 - val_loss: 0.6298 - val_output_1_loss: 0.6298
Epoch 8/1000
1/1 [==============================] - 0s 73ms/step - loss: 0.3049 - output_1_loss: 0.3049 - val_loss: 0.6121 - val_output_1_loss: 0.6121
Epoch 9/1000
1/1 [==============================] - 0s 71ms/step - loss: 0.2775 - output_1_loss: 0.2775 - val_loss: 0.5935 - val_output_1_loss: 0.5935
Epoch 10/1000
1/1 [==============================] - 0s 74ms/step - loss: 0.2565 - output_1_loss: 0.2565 - val_loss: 0.5754 - val_output_1_loss: 0.5754
Epoch 11/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.2538 - output_1_loss: 0.2538 - val_loss: 0.5619 - val_output_1_loss: 0.5619
Epoch 12/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.1970 - output_1_loss: 0.1970 - val_loss: 0.5483 - val_output_1_loss: 0.5483
Epoch 13/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.1913 - output_1_loss: 0.1913 - val_loss: 0.5311 - val_output_1_loss: 0.5311
Epoch 14/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.1658 - output_1_loss: 0.1658 - val_loss: 0.5115 - val_output_1_loss: 0.5115
Epoch 15/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.1510 - output_1_loss: 0.1510 - val_loss: 0.4924 - val_output_1_loss: 0.4924
Epoch 16/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.1357 - output_1_loss: 0.1357 - val_loss: 0.4758 - val_output_1_loss: 0.4758
Epoch 17/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.1274 - output_1_loss: 0.1274 - val_loss: 0.4636 - val_output_1_loss: 0.4636
Epoch 18/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.1136 - output_1_loss: 0.1136 - val_loss: 0.4552 - val_output_1_loss: 0.4552
Epoch 19/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0973 - output_1_loss: 0.0973 - val_loss: 0.4446 - val_output_1_loss: 0.4446
Epoch 20/1000
1/1 [==============================] - 0s 76ms/step - loss: 0.1444 - output_1_loss: 0.1444 - val_loss: 0.4319 - val_output_1_loss: 0.4319
Epoch 21/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0924 - output_1_loss: 0.0924 - val_loss: 0.4154 - val_output_1_loss: 0.4154
Epoch 22/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0810 - output_1_loss: 0.0810 - val_loss: 0.3973 - val_output_1_loss: 0.3973
Epoch 23/1000
1/1 [==============================] - 0s 71ms/step - loss: 0.0677 - output_1_loss: 0.0677 - val_loss: 0.3798 - val_output_1_loss: 0.3798
Epoch 24/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0577 - output_1_loss: 0.0577 - val_loss: 0.3642 - val_output_1_loss: 0.3642
Epoch 25/1000
1/1 [==============================] - 0s 79ms/step - loss: 0.0492 - output_1_loss: 0.0492 - val_loss: 0.3506 - val_output_1_loss: 0.3506
Epoch 26/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0410 - output_1_loss: 0.0410 - val_loss: 0.3388 - val_output_1_loss: 0.3388
Epoch 27/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0352 - output_1_loss: 0.0352 - val_loss: 0.3290 - val_output_1_loss: 0.3290
Epoch 28/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0275 - output_1_loss: 0.0275 - val_loss: 0.3190 - val_output_1_loss: 0.3190
Epoch 29/1000
1/1 [==============================] - 0s 66ms/step - loss: 0.0226 - output_1_loss: 0.0226 - val_loss: 0.3079 - val_output_1_loss: 0.3079
Epoch 30/1000
1/1 [==============================] - 0s 78ms/step - loss: 0.0194 - output_1_loss: 0.0194 - val_loss: 0.2964 - val_output_1_loss: 0.2964
Epoch 31/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0170 - output_1_loss: 0.0170 - val_loss: 0.2842 - val_output_1_loss: 0.2842
Epoch 32/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0151 - output_1_loss: 0.0151 - val_loss: 0.2717 - val_output_1_loss: 0.2717
Epoch 33/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0135 - output_1_loss: 0.0135 - val_loss: 0.2595 - val_output_1_loss: 0.2595
Epoch 34/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0123 - output_1_loss: 0.0123 - val_loss: 0.2474 - val_output_1_loss: 0.2474
Epoch 35/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0113 - output_1_loss: 0.0113 - val_loss: 0.2356 - val_output_1_loss: 0.2356
Epoch 36/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0104 - output_1_loss: 0.0104 - val_loss: 0.2245 - val_output_1_loss: 0.2245
Epoch 37/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0098 - output_1_loss: 0.0098 - val_loss: 0.2141 - val_output_1_loss: 0.2141
Epoch 38/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0092 - output_1_loss: 0.0092 - val_loss: 0.2045 - val_output_1_loss: 0.2045
Epoch 39/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0087 - output_1_loss: 0.0087 - val_loss: 0.1954 - val_output_1_loss: 0.1954
Epoch 40/1000
1/1 [==============================] - 0s 72ms/step - loss: 0.0083 - output_1_loss: 0.0083 - val_loss: 0.1870 - val_output_1_loss: 0.1870
Epoch 41/1000
1/1 [==============================] - 0s 76ms/step - loss: 0.0079 - output_1_loss: 0.0079 - val_loss: 0.1790 - val_output_1_loss: 0.1790
Epoch 42/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0076 - output_1_loss: 0.0076 - val_loss: 0.1715 - val_output_1_loss: 0.1715
Epoch 43/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0073 - output_1_loss: 0.0073 - val_loss: 0.1645 - val_output_1_loss: 0.1645
Epoch 44/1000
1/1 [==============================] - 0s 71ms/step - loss: 0.0071 - output_1_loss: 0.0071 - val_loss: 0.1581 - val_output_1_loss: 0.1581
Epoch 45/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0075 - output_1_loss: 0.0075 - val_loss: 0.1522 - val_output_1_loss: 0.1522
Epoch 46/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0071 - output_1_loss: 0.0071 - val_loss: 0.1473 - val_output_1_loss: 0.1473
Epoch 47/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0112 - output_1_loss: 0.0112 - val_loss: 0.1430 - val_output_1_loss: 0.1430
Epoch 48/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0121 - output_1_loss: 0.0121 - val_loss: 0.1388 - val_output_1_loss: 0.1388
Epoch 49/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0119 - output_1_loss: 0.0119 - val_loss: 0.1348 - val_output_1_loss: 0.1348
Epoch 50/1000
1/1 [==============================] - 0s 71ms/step - loss: 0.0140 - output_1_loss: 0.0140 - val_loss: 0.1311 - val_output_1_loss: 0.1311
Epoch 51/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0164 - output_1_loss: 0.0164 - val_loss: 0.1268 - val_output_1_loss: 0.1268
Epoch 52/1000
1/1 [==============================] - 0s 71ms/step - loss: 0.0225 - output_1_loss: 0.0225 - val_loss: 0.1233 - val_output_1_loss: 0.1233
Epoch 53/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0453 - output_1_loss: 0.0453 - val_loss: 0.1203 - val_output_1_loss: 0.1203
Epoch 54/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0162 - output_1_loss: 0.0162 - val_loss: 0.1180 - val_output_1_loss: 0.1180
Epoch 55/1000
1/1 [==============================] - 0s 66ms/step - loss: 0.0143 - output_1_loss: 0.0143 - val_loss: 0.1160 - val_output_1_loss: 0.1160
Epoch 56/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0164 - output_1_loss: 0.0164 - val_loss: 0.1141 - val_output_1_loss: 0.1141
Epoch 57/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0096 - output_1_loss: 0.0096 - val_loss: 0.1127 - val_output_1_loss: 0.1127
Epoch 58/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0095 - output_1_loss: 0.0095 - val_loss: 0.1125 - val_output_1_loss: 0.1125
Epoch 59/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0094 - output_1_loss: 0.0094 - val_loss: 0.1180 - val_output_1_loss: 0.1180
Epoch 60/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0112 - output_1_loss: 0.0112 - val_loss: 0.1251 - val_output_1_loss: 0.1251
Epoch 61/1000
1/1 [==============================] - 0s 50ms/step - loss: 0.0090 - output_1_loss: 0.0090 - val_loss: 0.1314 - val_output_1_loss: 0.1314
Epoch 62/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0079 - output_1_loss: 0.0079 - val_loss: 0.1149 - val_output_1_loss: 0.1149
Epoch 63/1000
1/1 [==============================] - 0s 55ms/step - loss: 0.0084 - output_1_loss: 0.0084 - val_loss: 0.1132 - val_output_1_loss: 0.1132
Epoch 64/1000
1/1 [==============================] - 0s 66ms/step - loss: 0.0084 - output_1_loss: 0.0084 - val_loss: 0.1125 - val_output_1_loss: 0.1125
Epoch 65/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0257 - output_1_loss: 0.0257 - val_loss: 0.1115 - val_output_1_loss: 0.1115
Epoch 66/1000
1/1 [==============================] - 0s 72ms/step - loss: 0.0073 - output_1_loss: 0.0073 - val_loss: 0.1098 - val_output_1_loss: 0.1098
Epoch 67/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0075 - output_1_loss: 0.0075 - val_loss: 0.1074 - val_output_1_loss: 0.1074
Epoch 68/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0100 - output_1_loss: 0.0100 - val_loss: 0.1053 - val_output_1_loss: 0.1053
Epoch 69/1000
1/1 [==============================] - 0s 68ms/step - loss: 0.0075 - output_1_loss: 0.0075 - val_loss: 0.1026 - val_output_1_loss: 0.1026
Epoch 70/1000
1/1 [==============================] - 0s 74ms/step - loss: 0.0074 - output_1_loss: 0.0074 - val_loss: 0.1002 - val_output_1_loss: 0.1002
Epoch 71/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0072 - output_1_loss: 0.0072 - val_loss: 0.0972 - val_output_1_loss: 0.0972
Epoch 72/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0071 - output_1_loss: 0.0071 - val_loss: 0.0939 - val_output_1_loss: 0.0939
Epoch 73/1000
1/1 [==============================] - 0s 69ms/step - loss: 0.0070 - output_1_loss: 0.0070 - val_loss: 0.0927 - val_output_1_loss: 0.0927
Epoch 74/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0069 - output_1_loss: 0.0069 - val_loss: 0.0919 - val_output_1_loss: 0.0919
Epoch 75/1000
1/1 [==============================] - 0s 55ms/step - loss: 0.0121 - output_1_loss: 0.0121 - val_loss: 0.0924 - val_output_1_loss: 0.0924
Epoch 76/1000
1/1 [==============================] - 0s 70ms/step - loss: 0.0101 - output_1_loss: 0.0101 - val_loss: 0.0915 - val_output_1_loss: 0.0915
Epoch 77/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0068 - output_1_loss: 0.0068 - val_loss: 0.0919 - val_output_1_loss: 0.0919
Epoch 78/1000
1/1 [==============================] - 0s 67ms/step - loss: 0.0090 - output_1_loss: 0.0090 - val_loss: 0.0912 - val_output_1_loss: 0.0912
Epoch 79/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0865 - output_1_loss: 0.0865 - val_loss: 0.1063 - val_output_1_loss: 0.1063
Epoch 80/1000
1/1 [==============================] - 0s 50ms/step - loss: 0.0106 - output_1_loss: 0.0106 - val_loss: 0.1057 - val_output_1_loss: 0.1057
Epoch 81/1000
1/1 [==============================] - 0s 49ms/step - loss: 0.0810 - output_1_loss: 0.0810 - val_loss: 0.1624 - val_output_1_loss: 0.1624
Epoch 82/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.2498 - output_1_loss: 0.2498 - val_loss: 0.1161 - val_output_1_loss: 0.1161
Epoch 83/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.1384 - output_1_loss: 0.1384 - val_loss: 0.1051 - val_output_1_loss: 0.1051
Epoch 84/1000
1/1 [==============================] - 0s 53ms/step - loss: 0.0824 - output_1_loss: 0.0824 - val_loss: 0.1046 - val_output_1_loss: 0.1046
Epoch 85/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0694 - output_1_loss: 0.0694 - val_loss: 0.1179 - val_output_1_loss: 0.1179
Epoch 86/1000
1/1 [==============================] - 0s 49ms/step - loss: 0.0584 - output_1_loss: 0.0584 - val_loss: 0.1657 - val_output_1_loss: 0.1657
Epoch 87/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0534 - output_1_loss: 0.0534 - val_loss: 0.1906 - val_output_1_loss: 0.1906
Epoch 88/1000
1/1 [==============================] - 0s 45ms/step - loss: 0.0546 - output_1_loss: 0.0546 - val_loss: 0.2033 - val_output_1_loss: 0.2033
Epoch 89/1000
1/1 [==============================] - 0s 49ms/step - loss: 0.0438 - output_1_loss: 0.0438 - val_loss: 0.2133 - val_output_1_loss: 0.2133
Epoch 90/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0394 - output_1_loss: 0.0394 - val_loss: 0.2157 - val_output_1_loss: 0.2157
Epoch 91/1000
1/1 [==============================] - 0s 51ms/step - loss: 0.0484 - output_1_loss: 0.0484 - val_loss: 0.1848 - val_output_1_loss: 0.1848
Epoch 92/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0592 - output_1_loss: 0.0592 - val_loss: 0.1787 - val_output_1_loss: 0.1787
Epoch 93/1000
1/1 [==============================] - 0s 46ms/step - loss: 0.0401 - output_1_loss: 0.0401 - val_loss: 0.1706 - val_output_1_loss: 0.1706
Epoch 94/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0394 - output_1_loss: 0.0394 - val_loss: 0.1625 - val_output_1_loss: 0.1625
Epoch 95/1000
1/1 [==============================] - 0s 48ms/step - loss: 0.0388 - output_1_loss: 0.0388 - val_loss: 0.1562 - val_output_1_loss: 0.1562
Epoch 96/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0309 - output_1_loss: 0.0309 - val_loss: 0.1505 - val_output_1_loss: 0.1505
Epoch 97/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0325 - output_1_loss: 0.0325 - val_loss: 0.1429 - val_output_1_loss: 0.1429
Epoch 98/1000
1/1 [==============================] - 0s 46ms/step - loss: 0.0338 - output_1_loss: 0.0338 - val_loss: 0.1334 - val_output_1_loss: 0.1334
Epoch 99/1000
1/1 [==============================] - 0s 57ms/step - loss: 0.0287 - output_1_loss: 0.0287 - val_loss: 0.1284 - val_output_1_loss: 0.1284
Epoch 100/1000
1/1 [==============================] - 0s 46ms/step - loss: 0.0257 - output_1_loss: 0.0257 - val_loss: 0.1101 - val_output_1_loss: 0.1101
Epoch 101/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0217 - output_1_loss: 0.0217 - val_loss: 0.1084 - val_output_1_loss: 0.1084
Epoch 102/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0182 - output_1_loss: 0.0182 - val_loss: 0.1114 - val_output_1_loss: 0.1114
Epoch 103/1000
1/1 [==============================] - 0s 46ms/step - loss: 0.0171 - output_1_loss: 0.0171 - val_loss: 0.1153 - val_output_1_loss: 0.1153
Epoch 104/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0147 - output_1_loss: 0.0146 - val_loss: 0.1175 - val_output_1_loss: 0.1175
Epoch 105/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0160 - output_1_loss: 0.0160 - val_loss: 0.1170 - val_output_1_loss: 0.1170
Epoch 106/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0137 - output_1_loss: 0.0137 - val_loss: 0.1136 - val_output_1_loss: 0.1136
Epoch 107/1000
1/1 [==============================] - 0s 47ms/step - loss: 0.0133 - output_1_loss: 0.0133 - val_loss: 0.1100 - val_output_1_loss: 0.1100
Epoch 108/1000
1/1 [==============================] - 0s 72ms/step - loss: 0.0145 - output_1_loss: 0.0145 - val_loss: 0.1066 - val_output_1_loss: 0.1066
<keras.callbacks.History at 0x7f4a8968b1d0>
from sklearn.metrics import roc_auc_score, average_precision_score
val_preds, val_imps = tabnet.predict(val_ds)
print('Test ROC AUC', np.round(roc_auc_score(val_y, val_preds[:, 1]), 4))
print('Test PR AUC', np.round(average_precision_score(val_y, val_preds[:, 1]), 4))
1/1 [==============================] - 1s 584ms/step
Test ROC AUC 0.6011
Test PR AUC 0.025
Test Submission
test.head()
| TransactionID | TransactionDT | TransactionAmt | ProductCD | card1 | card2 | card3 | card4 | card5 | card6 | ... | id_32 | id_33 | id_34 | id_35 | id_36 | id_37 | id_38 | DeviceType | DeviceInfo | hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3663549 | 18403224 | 31.95 | W | 10409 | 111.0 | 150.0 | visa | 226.0 | debit | ... | missing | missing | missing | missing | missing | missing | missing | missing | missing | 0.0 |
| 1 | 3663550 | 18403263 | 49.00 | W | 4272 | 111.0 | 150.0 | visa | 226.0 | debit | ... | missing | missing | missing | missing | missing | missing | missing | missing | missing | 0.0 |
| 2 | 3663551 | 18403310 | 171.00 | W | 4476 | 574.0 | 150.0 | visa | 226.0 | debit | ... | missing | missing | missing | missing | missing | missing | missing | missing | missing | 0.0 |
| 3 | 3663552 | 18403310 | 284.95 | W | 10989 | 360.0 | 150.0 | visa | 166.0 | debit | ... | missing | missing | missing | missing | missing | missing | missing | missing | missing | 0.0 |
| 4 | 3663553 | 18403317 | 67.95 | W | 18018 | 452.0 | 150.0 | mastercard | 117.0 | debit | ... | missing | missing | missing | missing | missing | missing | missing | missing | missing | 0.0 |
5 rows × 422 columns
test_preds, test_imp = tabnet.predict(test_ds)
submission_df = pd.DataFrame({"TransactionID": test['TransactionID'].values,
'isFraud': test_preds[:, 1]})
submission_df.to_csv('tabnet_sumbission.csv', index=False)
1/1 [==============================] - 1s 576ms/step
댓글남기기