[Feedback Prize - English Language Learning] Speeding up Transformer w/ Optimization Strategies
Introduction
state-of-the-art 또는 SOTA model을 훈련시키기 위해서는 GPU가 절대적으로 필요합니다. 그리고 Google Colab이나 Kaggle에서 사용할 수 있다고 해도 메모리 제약 문제가 여전히 발생합니다.
우리는 training을 위해 large batch, large model, longer epochs 등을 시도할 때마다 OOM(메모리 부족) 또는 GPU 런타임 제한 도달 오류를 보는 데 다소 익숙해졌습니다.
이 notebook은 심층 분석 및 코드와 함께 다양한 optimization 전략을 사용하여 이러한 문제를 해결할 수 있는 방법에 대해 설명합니다.
Problem
문제는 transformer에 대해 이야기할 때 훨씬 더 분명합니다. transformer는 memory intensive합니다. 따라서, 더 큰 모델을 training하거나 더 긴 epoch로 tarining하는 동안 메모리가 부족하거나 런타임 제한을 초과할 가능성이 상당히 높습니다.
이 competition에서처럼 loss는 불안정합니다. 최고의 성능 모델을 찾는 방법은 매 epoch 이후보다 각 epoch 내에서 더 자주 평가하는 것입니다. 이는 intensive process이며 training이 fold에서 완료되면 GPU 런타임 제한에 도달할 수 있습니다.
Solution
이러한 문제를 해결하기 위해 즉시 사용 가능한 몇 가지 유망한 잘 알려진 전략이 있으며 각 전략에는 각각의 이점이 있습니다.
- Dyanmic Padding and Uniform Length Batching
- Gradient Accumulation
- Freeze Embedding
- Numeric Precision Reduction
- Gradient Checkpointing
Note 1: 이러한 모든 optimization은 single-GPU에만 초점을 맞춥니다. 이러한 optimization는 multi-GPU에서도 작동하지만 multi-GPU 설정에는 DataParallel, DataParallelModel, ZeRO 등과 같은 고급 기술이 있어 트랜스포머를 가속화하는 데 훨씬 더 효과적입니다.
Note 2: Gradient Checkpointing은 계산 시간을 증가시키지만 single pass에서 더 큰 batch size를 맞추는 데 도움이 됩니다. 그래서 이것을 포함시켰습니다.
Contents
- Dynamic Padding and Uniform Length Batching (Smart Batching)
- Introduction
- Dyanmic Padding
- Uniform Length Batching
- Read Dataset
- Load Tokenizer
- Tokenize without Padding
- Sort by Length
- Random Batch Selection
- Add Padding
- Comparison I
- Unified Function - make_smart_batches
- Smart Batching with DataLoader, Collater, Sampler
- Components
- Comparison II
- Conclusion
- References & Resources
- Introduction
- Freeze Embedding
- Introduction
- Idea
- Splits Analysis
- Implementation
- Conclusion
- References & Resources
- Numeric Precision Reduction
- Introduction
- Floating Point Representation
- How to Use?
- Special Case
- References & Resources
- Gradient Accumulation
- Introduction
- Implementation
- References & Resources
- Gradient Checkpointing
- Introduction
- Idea
- References & Resources
- Ending Notes
What’s New?
- SWA, Apex AMP & Interpreting Transformers in Torch notebook은 PyTorch를 사용하는 transformer에서 NVIDIA Apex를 사용한 Stochastic Weight Averaging 기법을 구현한 것입니다. notbook은 또한 NLP 모델 이해를 위한 플랫폼인 LIT(Language Interpretability Tool)를 사용하여 Transformers를 대화식으로 해석하는 방법을 구현합니다.
다음을 위한 자세한 설명과 코드 구현이 있습니다.
- SWA
- Apex AMP
- Weighted Layer Pooling
- MADGRAD Optimizer
- Grouped LLRD
- Language Interpretibility Tool
- Attention Visualization
- Saliency Maps
- Integrated Gradients
- LIME
- Embedding Space (UMAP & PCA)
- Counterfactual generation
- And many more …
- Utilizing Transformer Representations Efficiently(추후, 링크 추가) notebook은 output layer를 추가하는 것보다 훨씬 더 많은 작업을 수행하기 위해 이러한 output 및 hidden state를 활용할 수 있는 다양한 방법을 보여줍니다. 아래는 모든 technique에 대한 코드 구현 및 자세한 설명이 있습니다.
- Pooler Output
- Last Hidden State Output
- CLS Embeddings
- Mean Pooling
- Max Pooling
- Mean + Max Pooling
- Conv1D Pooling
- Hidden Layers Output
- Layerwise CLS Embeddings
- Concatenate Pooling
- Weighted Layer Pooling
- LSTM / GRU Pooling
- Attention Pooling
- WKPooling
- On Stability of Few-Sample Transformer Fine-Tuning(추후, 링크 추가) notebook은 few-sample fine-tuning 안정성을 높이기 위해 다양한 해결책을 검토했으며, 단순 fine-tuning 방법에 비해 상당한 성능 향상을 보여줍니다. notebook에 설명된 방법은 다음과 같습니다.
- Debiasing Omission In BertADAM
- Re-Initializing Transformer Layers
- Utilizing Intermediate Layers
- Layer-wise Learning Rate Decay (LLRD)
- Mixout Regularization
- Pre-trained Weight Decay
- Stochastic Weight Averaging.
Dynamic Padding and Uniform Length Batching
Introduction
batch of sequences에서 neural network를 training하려면 batch matrix representation을 구축하기 위해 동일한 길이를 가져야 합니다. 실제 NLP dataset는 항상 다양한 길이의 텍스트로 구성되기 때문에 일부 sequence는 잘라서 짧게 만들고 일부 sequence는 마지막에 “pad” token이라는 반복되는 가짜 token을 추가하여 더 길게 만들어야 합니다.
pad token은 실제 단어를 나타내지 않기 때문에 대부분의 계산이 완료되면 loss를 계산하기 전에 PAD를 식별하는 각 sample에 대한 “attention mask” matrix를 통해 pad token signal에 0을 곱하여 pad token signal을 지워 token을 무시하라고 Transformer에게 지시합니다.

예를 들어, 이 competition에서 한 번에 여러 sample을 RoBERTa에 전달하기 위해 모든 문장을 250의 “fixed length”로 채웁니다. 이것이 제가 모든 예에서 사용한 standard 접근 방식입니다. 코드 측면에서 구현하기 가장 간단합니다.
Dynamic Padding
여기서는 추가된 pad token의 수를 제한하여 전체 training 세트에 대한 fixed value 대신 각 mini batch의 가장 긴 sequence 길이에 도달하도록 제한합니다. 추가된 token의 수가 mini batch에 따라 변경되기 때문에 “dynamic” padding이라고 합니다.

Uniform Length Batching
logic을 더욱 강화하기 위해 유사한 길이 sequence로 구성된 batch를 생성함으로써 mini batch의 대부분의 sequence가 짧고 동일한 mini batch의 하나의 sequence가 매우 길어 각각에 많은 pad token을 추가해야 하는 극단적인 경우를 피합니다.

Note: 위의 그림에서 선택한 batch는 차례대로 있지만, 실제로는 training data의 순서에 더 많은 randomness를 허용하기 위해 batch를 더 무작위로 선택합니다.
Read Dataset
!pip install transformers
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting transformers
Downloading transformers-4.24.0-py3-none-any.whl (5.5 MB)
[K |████████████████████████████████| 5.5 MB 14.3 MB/s
[?25hRequirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (2022.6.2)
Collecting huggingface-hub<1.0,>=0.10.0
Downloading huggingface_hub-0.11.0-py3-none-any.whl (182 kB)
[K |████████████████████████████████| 182 kB 65.7 MB/s
[?25hCollecting tokenizers!=0.11.3,<0.14,>=0.11.1
Downloading tokenizers-0.13.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (7.6 MB)
[K |████████████████████████████████| 7.6 MB 58.5 MB/s
[?25hRequirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.7/dist-packages (from transformers) (21.3)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from transformers) (3.8.0)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.7/dist-packages (from transformers) (4.64.1)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from transformers) (2.23.0)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.7/dist-packages (from transformers) (6.0)
Requirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from transformers) (4.13.0)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.7/dist-packages (from transformers) (1.21.6)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub<1.0,>=0.10.0->transformers) (4.1.1)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=20.0->transformers) (3.0.9)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->transformers) (3.10.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (1.24.3)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2022.9.24)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->transformers) (2.10)
Installing collected packages: tokenizers, huggingface-hub, transformers
Successfully installed huggingface-hub-0.11.0 tokenizers-0.13.2 transformers-4.24.0
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from transformers import AutoTokenizer
from IPython.display import clear_output
try:
# kaggle notebook
train = pd.read_csv('../input/commonlitreadabilityprize/train.csv', low_memory=False)
test = pd.read_csv('../input/commonlitreadabilityprize/sample_submission.csv', low_memory=False)
except:
# colab
from google.colab import files
files.upload() # Upload your Kaggle API Token
!mkdir ~/.kaggle
!mv kaggle.json ~/.kaggle
!chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions download -c commonlitreadabilityprize
!unzip commonlitreadabilityprize.zip
train = pd.read_csv('train.csv', low_memory=False)
test = pd.read_csv('sample_submission.csv', low_memory=False)
<input type="file" id="files-e56826b7-d4bf-42b9-ab1e-0c1de54bc602" name="files[]" multiple disabled
style="border:none" />
<output id="result-e56826b7-d4bf-42b9-ab1e-0c1de54bc602">
Upload widget is only available when the cell has been executed in the
current browser session. Please rerun this cell to enable.
</output>
<script>// Copyright 2017 Google LLC // // Licensed under the Apache License, Version 2.0 (the "License"); // you may not use this file except in compliance with the License. // You may obtain a copy of the License at // // http://www.apache.org/licenses/LICENSE-2.0 // // Unless required by applicable law or agreed to in writing, software // distributed under the License is distributed on an "AS IS" BASIS, // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. // See the License for the specific language governing permissions and // limitations under the License.
Saving kaggle.json to kaggle.json
Downloading commonlitreadabilityprize.zip to /content
88% 1.00M/1.13M [00:00<00:00, 1.99MB/s]
100% 1.13M/1.13M [00:00<00:00, 2.20MB/s]
Archive: commonlitreadabilityprize.zip
inflating: sample_submission.csv
inflating: test.csv
inflating: train.csv
Load Tokenizer
RoBERTa-base tokenizer를 사용합니다.
tokenizer = AutoTokenizer.from_pretrained('roberta-base')
clear_output()
Tokenize Without Padding
Peak GPU Memory Use
이 technique를 적용할 때에도 여전히 input을 특정 최대 길이로 자르고 싶을 수 있습니다. GPU에 맞추기에는 너무 긴 하나의 배치만 있으면 training이 실패할 것입니다! 따라서, smart batching을 사용하더라도 512보다 낮은 값으로 자르는 것이 좋습니다.
Tokenize, but don’t pad
모든 sample을 토큰화하고 token을 해당 ID에 mapping하는 것으로 시작하겠습니다. 또한, sequence를 선택한 max_len으로 자르고 special token을 추가할 것입니다. 하지만, 아직 padding을 하진 않습니다.
def good_update_interval(total_iters, num_desired_updates):
# find intervals for printing updates
exact_interval = total_iters / num_desired_updates
order_of_mag = len(str(total_iters)) - 1
round_mag = order_of_mag - 1
update_interval = int(round(exact_interval, -round_mag))
if update_interval == 0:
update_interval = 1
return update_interval
input_ids = []
train_text = train.excerpt.values.tolist()
train_targets = train.target.values.tolist()
max_len = 350
print('Tokenizing {:,} training samples...'.format(len(train_text)))
update_interval = good_update_interval(total_iters=len(train_text), num_desired_updates=5)
for text in train_text:
if ((len(input_ids) % update_interval) == 0):
print(' Tokenized {:,} samples.'.format(len(input_ids)))
input_id = tokenizer.encode(
text=text,
add_special_tokens=True,
max_length=max_len,
truncation=True,
padding=False
)
input_ids.append(input_id)
print('DONE.')
print('{:>10,} samples'.format(len(input_ids)))
Tokenizing 2,834 training samples...
Tokenized 0 samples.
Tokenized 600 samples.
Tokenized 1,200 samples.
Tokenized 1,800 samples.
Tokenized 2,400 samples.
DONE.
2,834 samples
Sort by length
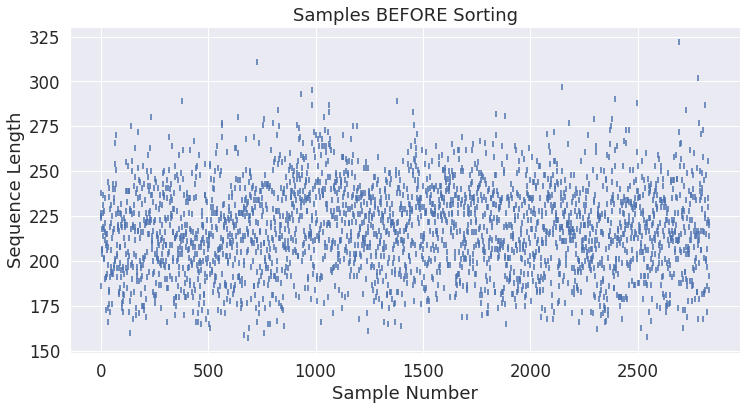
정렬되지 않은 원래 순서대로 sample의 길이를 살펴보겠습니다. 아래 plot은 샘플 길이가 크게 다르고 정렬되지 않았음을 확인합니다.
unsorted_lengths = [len(x) for x in input_ids]
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid')
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12,6)
plt.scatter(range(0, len(unsorted_lengths)), unsorted_lengths, marker="|")
plt.xlabel('Sample Number')
plt.ylabel('Sequence Length')
plt.title('Samples BEFORE Sorting')
plt.show()
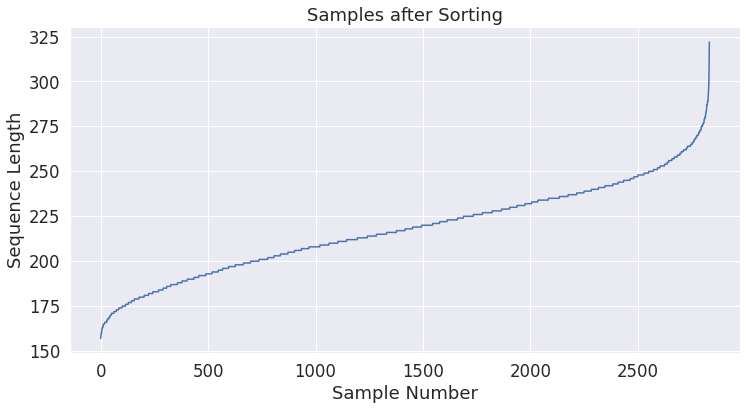
이제 동일한(또는, 적어도 유사한) 길이의 batch를 생성하고 동일한 plot을 다시 생성할 수 있도록 길이별로 sample을 정렬합니다.
sorted_input_ids = sorted(zip(input_ids, train_targets), key=lambda x: len(x[0]))
print('Shortest sample:', len(sorted_input_ids[0][0]))
print('Longest sample:', len(sorted_input_ids[-1][0]))
sorted_lengths = [len(s[0]) for s in sorted_input_ids]
Shortest sample: 157
Longest sample: 322
import matplotlib.pyplot as plt
import seaborn as sns
# Use plot styling from seaborn.
sns.set(style='darkgrid')
# Increase the plot size and font size.
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12,6)
plt.plot(range(0, len(sorted_lengths)), sorted_lengths)
plt.xlabel('Sample Number')
plt.ylabel('Sequence Length')
plt.title('Samples after Sorting')
plt.show()
Random Batch Selection
이제 batch를 선택할 준비가 되었습니다. batch를 순서대로 나누지 않고 선택 항목에 어느 정도 randomness를 추가합니다.
process는 다음과 같습니다:
- (sorted) sample list에서 임의의 시작점을 선택합니다.
- 해당 지점에서 시작하여 인접한 batch of samples를 가져옵니다.
- list에서 해당 sample을 삭제하고 모든 sample을 가져올 때까지 반복합니다.
이로 인해 list 일부가 fragmentation될 것이며, 이는 batch를 정렬된 순서로 분할하는 것만큼 효율적이지 않을 것입니다.
batch_size = 24
import random
batch_ordered_sentences = []
batch_ordered_labels = []
print('Creating training batches of size {:}'.format(batch_size))
while len(sorted_input_ids) > 0:
if ((len(batch_ordered_sentences) % 50) == 0):
print(' Selected {:,} batches.'.format(len(batch_ordered_sentences)))
to_take = min(batch_size, len(sorted_input_ids))
select = random.randint(0, len(sorted_input_ids) - to_take)
batch = sorted_input_ids[select:(select + to_take)]
batch_ordered_sentences.append([s[0] for s in batch])
batch_ordered_labels.append([s[1] for s in batch])
del sorted_input_ids[select:select + to_take]
print('\n DONE - {:,} batches.'.format(len(batch_ordered_sentences)))
Creating training batches of size 24
Selected 0 batches.
Selected 50 batches.
Selected 100 batches.
DONE - 119 batches.
Add Padding
우리는 batch를 만들었지만 대부분은 다른 길이의 sequence를 포함할 것입니다. batch의 GPU parallel processing을 활용하려면 batch 내의 모든 sequence 길이가 동일해야 합니다.
이는 우리가 약간의 padding을 해야 한다는 것을 의미합니다!
또한, 여기에서 attention mask를 만들고 fine-tuning 단계를 준비하기 위해 모든 것을 PyTorch tensor로 cast합니다.
import torch
inputs = []
attn_masks = []
targets = []
for (batch_inputs, batch_labels) in zip(batch_ordered_sentences, batch_ordered_labels):
batch_padded_inputs = []
batch_attn_masks = []
max_size = max([len(sen) for sen in batch_inputs])
for sen in batch_inputs:
num_pads = max_size - len(sen)
padded_input = sen + [tokenizer.pad_token_id] * num_pads
attn_mask = [1] * len(sen) + [0] * num_pads
batch_padded_inputs.append(padded_input)
batch_attn_masks.append(attn_mask)
inputs.append(torch.tensor(batch_padded_inputs))
attn_masks.append(torch.tensor(batch_attn_masks))
targets.append(torch.tensor(batch_labels))
Comparison
이제 data가 준비되었으므로 smart batching을 사용한 후, training data의 총 token 수를 계산할 수 있습니다.
padded_lengths = []
for batch in inputs:
for s in batch:
padded_lengths.append(len(s))
smart_token_count = np.sum(padded_lengths)
fixed_token_count = len(train_text) * max_len
prcnt_reduced = (fixed_token_count - smart_token_count) / float(fixed_token_count)
print('Total tokens:')
print(' Fixed Padding: {:,}'.format(fixed_token_count))
print(' Smart Batching: {:,} ({:.2%} less)'.format(smart_token_count, prcnt_reduced))
Total tokens:
Fixed Padding: 991,900
Smart Batching: 624,724 (37.02% less)
All in One - make_smart_batches
“Smart Batching” 섹션의 모든 단계를 하나의(재사용 가능) function으로 합칩니다. training set와 test set 모두에 smart batching을 적용하기 위해 자신의 notebook에서 이것을 사용할 수 있습니다.
def make_smart_batches(text_samples, labels, batch_size):
print('Creating Smart Batches from {:,} examples with batch size {:,}...\n'.format(len(text_samples), batch_size))
# =========================
# Tokenize & Truncate
# =========================
full_input_ids = []
print('Tokenizing {:,} samples...'.format(len(labels)))
update_interval = good_update_interval(total_iters=len(labels), num_desired_updates=10)
for text in text_samples:
# Report progress.
if ((len(full_input_ids) % update_interval) == 0):
print(' Tokenized {:,} samples.'.format(len(full_input_ids)))
# Tokenize the sample.
input_ids = tokenizer.encode(text=text, # Text to encode.
add_special_tokens=True, # Do add specials.
max_length=max_len, # Do Truncate!
truncation=True, # Do Truncate!
padding=False) # DO NOT pad.
# Add the tokenized result to our list.
full_input_ids.append(input_ids)
print('DONE.')
print('{:>10,} samples\n'.format(len(full_input_ids)))
# =========================
# Select Batches
# =========================
samples = sorted(zip(full_input_ids, labels), key=lambda x: len(x[0]))
print('{:>10,} samples after sorting\n'.format(len(samples)))
import random
# List of batches that we'll construct.
batch_ordered_sentences = []
batch_ordered_labels = []
print('Creating batches of size {:}...'.format(batch_size))
# Choose an interval on which to print progress updates.
update_interval = good_update_interval(total_iters=len(samples), num_desired_updates=10)
# Loop over all of the input samples...
while len(samples) > 0:
# Report progress.
if ((len(batch_ordered_sentences) % update_interval) == 0 \
and not len(batch_ordered_sentences) == 0):
print(' Selected {:,} batches.'.format(len(batch_ordered_sentences)))
# `to_take` is our actual batch size. It will be `batch_size` until
# we get to the last batch, which may be smaller.
to_take = min(batch_size, len(samples))
# Pick a random index in the list of remaining samples to start
# our batch at.
select = random.randint(0, len(samples) - to_take)
# Select a contiguous batch of samples starting at `select`.
#print("Selecting batch from {:} to {:}".format(select, select+to_take))
batch = samples[select:(select + to_take)]
#print("Batch length:", len(batch))
# Each sample is a tuple--split them apart to create a separate list of
# sequences and a list of labels for this batch.
batch_ordered_sentences.append([s[0] for s in batch])
batch_ordered_labels.append([s[1] for s in batch])
# Remove these samples from the list.
del samples[select:select + to_take]
print('\n DONE - Selected {:,} batches.\n'.format(len(batch_ordered_sentences)))
# =========================
# Add Padding
# =========================
print('Padding out sequences within each batch...')
py_inputs = []
py_attn_masks = []
py_labels = []
# For each batch...
for (batch_inputs, batch_labels) in zip(batch_ordered_sentences, batch_ordered_labels):
# New version of the batch, this time with padded sequences and now with
# attention masks defined.
batch_padded_inputs = []
batch_attn_masks = []
# First, find the longest sample in the batch.
# Note that the sequences do currently include the special tokens!
max_size = max([len(sen) for sen in batch_inputs])
# For each input in this batch...
for sen in batch_inputs:
# How many pad tokens do we need to add?
num_pads = max_size - len(sen)
# Add `num_pads` padding tokens to the end of the sequence.
padded_input = sen + [tokenizer.pad_token_id]*num_pads
# Define the attention mask--it's just a `1` for every real token
# and a `0` for every padding token.
attn_mask = [1] * len(sen) + [0] * num_pads
# Add the padded results to the batch.
batch_padded_inputs.append(padded_input)
batch_attn_masks.append(attn_mask)
# Our batch has been padded, so we need to save this updated batch.
# We also need the inputs to be PyTorch tensors, so we'll do that here.
# Todo - Michael's code specified "dtype=torch.long"
py_inputs.append(torch.tensor(batch_padded_inputs))
py_attn_masks.append(torch.tensor(batch_attn_masks))
py_labels.append(torch.tensor(batch_labels))
print(' DONE.')
# Return the smart-batched dataset!
return (py_inputs, py_attn_masks, py_labels)
(py_inputs, py_attn_masks, py_labels) = make_smart_batches(train_text, train_targets, batch_size)
Creating Smart Batches from 2,834 examples with batch size 24...
Tokenizing 2,834 samples...
Tokenized 0 samples.
Tokenized 300 samples.
Tokenized 600 samples.
Tokenized 900 samples.
Tokenized 1,200 samples.
Tokenized 1,500 samples.
Tokenized 1,800 samples.
Tokenized 2,100 samples.
Tokenized 2,400 samples.
Tokenized 2,700 samples.
DONE.
2,834 samples
2,834 samples after sorting
Creating batches of size 24...
DONE - Selected 119 batches.
Padding out sequences within each batch...
DONE.
Smart Batching with DataLoader, Collator, Sampler
이 섹션은 PyTorch DataLoader class를 사용하여 보다 formal한 방식으로 위의 smart batching을 구현합니다.
Components
함께 작업할 4개의 주요 component가 있습니다.
- Dataset - sample과 그에 해당하는 label 저장
- DataLoader - sample에 쉬운 접근이 가능하도록 Dataset 주위에 iterable을 wrapping
- Sampler - data loading에 사용될 sequence의 index를 명시
- Collator - sample list를 batch로 collate
import random
import numpy as np
import multiprocessing
import more_itertools
import torch
import torch.nn as nn
from torch.utils.data import Sampler, Dataset, DataLoader
SmartBatchingDataset은 excerpts를 토큰화하고 sequence로 변환하여 sample을 저장합니다.
class SmartBatchingDataset(Dataset):
def __init__(self, df, tokenizer):
super().__init__()
self._data = (
f"{tokenizer.bos_token} " + df.excerpt + f" {tokenizer.eos_token}"
).apply(tokenizer.tokenize).apply(tokenizer.convert_tokens_to_ids).to_list()
self._targets = None
if 'target' in df.columns:
self._targets = df.target.tolist()
self.sampler = None
def __len__(self):
return len(self._data)
def __getitem__(self, item):
if self._targets is not None:
return self._data[item], self._targets[item]
else:
return self._data[item]
def get_dataloader(self, batch_size, max_len, pad_id):
self.sampler = SmartBatchingSampler(
data_source=self._data,
batch_size=batch_size
)
collate_fn = SmartBatchingCollate(
targets=self._targets,
max_length=max_len,
pad_token_id=pad_id
)
dataloader = DataLoader(
dataset=self,
batch_size=batch_size,
sampler=self.sampler,
collate_fn=collate_fn,
num_workers=(multiprocessing.cpu_count()-1),
pin_memory=True
)
return dataloader
SmartBatchingSampler는 sequence를 길이별로 정렬하고 “batch_size” 크기의 batch를 만들고, shuffle하고, 인덱스를 return합니다.
class SmartBatchingSampler(Sampler):
def __init__(self, data_source, batch_size):
super().__init__(data_source)
self.len = len(data_source)
sample_lengths = [len(seq) for seq in data_source]
argsort_inds = np.argsort(sample_lengths) # 정렬하는 index 반환
self.batches = list(more_itertools.chunked(argsort_inds, n=batch_size)) # batch_size로 리스트를 나눠준다
self._backsort_inds = None
def __iter__(self):
if self.batches:
last_batch = self.batches.pop(-1)
np.random.shuffle(self.batches)
self.batches.append(last_batch)
self._inds = list(more_itertools.flatten(self.batches))
yield from self._inds
def __len__(self):
return self.len
@property
def backsort_inds(self):
if self._backsort_inds is None:
self._backsort_inds = np.argsort(self._inds)
return self._backsort_inds
SmartBatchingCollate는 가장 높은 sequence 길이까지 padding을 추가하고, batch에서 각 sample의 attention mask와 target을 만듭니다.
class SmartBatchingCollate:
def __init__(self, targets, max_length, pad_token_id):
self._targets = targets
self._max_length = max_length
self._pad_token_id = pad_token_id
def __call__(self, batch):
if self._targets is not None:
sequences, targets = list(zip(*batch))
else:
sequences = list(batch)
input_ids, attention_mask = self.pad_sequence(
sequences,
max_sequence_length=self._max_length,
pad_token_id=self._pad_token_id
)
if self._targets is not None:
output = input_ids, attention_mask, torch.tensor(targets)
else:
output = input_ids, attention_mask
return output
def pad_sequence(self, sequence_batch, max_sequence_length, pad_token_id):
max_batch_len = max(len(sequence) for sequence in sequence_batch)
max_len = min(max_batch_len, max_sequence_length)
padded_sequences, attention_masks = [[] for i in range(2)]
attend, no_attend = 1, 0
for sequence in sequence_batch:
# As discussed above, truncate if exceeds max_len
new_sequence = list(sequence[:max_len])
attention_mask = [attend] * len(new_sequence)
pad_length = max_len - len(new_sequence)
new_sequence.extend([pad_token_id] * pad_length)
attention_mask.extend([no_attend] * pad_length)
padded_sequences.append(new_sequence)
attention_masks.append(attention_mask)
padded_sequences = torch.tensor(padded_sequences)
attention_masks = torch.tensor(attention_masks)
return padded_sequences, attention_masks
여기에서 Dataset와 DataLoader를 생성하고, aataloader를 반복문을 통해 총 token 수를 확인하고, comparison study를 수행합니다.
dataset = SmartBatchingDataset(train, tokenizer)
dataloader = dataset.get_dataloader(batch_size=24, max_len=max_len, pad_id=tokenizer.pad_token_id)
padded_lengths = []
for batch_idx, (input_ids, attention_mask, targets) in enumerate(dataloader):
for s in input_ids:
padded_lengths.append(len(s))
smart_token_count = np.sum(padded_lengths)
fixed_token_count = len(train_text) * max_len
prcnt_reduced = (fixed_token_count - smart_token_count) / float(fixed_token_count)
print('Total tokens:')
print(' Fixed Padding: {:,}'.format(fixed_token_count))
print(' Smart Batching: {:,} ({:.2%} less)'.format(smart_token_count, prcnt_reduced))
Total tokens:
Fixed Padding: 991,900
Smart Batching: 621,694 (37.32% less)
Comparison II
위의 random batch selection technique와 비교하여 DataLoader의 경우, framentation은 없지만 randomness는 감소합니다.
- Fixed Padding (MaxLen-350 & BS-24): 991,900 tokens
- Smart Batching with Random Batch: 623,780 (37.11% less)
- Smart Batching with DataLoader: 621,694 (37.32% less)
Conclusion
이 technique는 accuracy를 감소시키지 않고(경우에 따라 개선하기도 함) 지속적으로 상당한 시간 단축을 제공하는 것으로 나타났습니다. 이 technique는 transformer 사용자가 사용해야 하는 낮은 곳에 매달린 과일과 같습니다.
References and Resources
- Smart Batching Tutorial - Speed Up BERT Training by Chris McCormick. DataLoader 부분을 제외하고 위에서 본 거의 모든 것의 main source입니다.
- Divide Hugging Face Transformers training time by 2 or more by Michaël Benesty. Chris McCormick Smart Batching tutorial의 inspiration
- Accelerating recurrent neural network training using sequence bucketing and multi-GPU data parallelization
- Jigsaw Multilingual Toxic Comment Classification - 4th Place Solution
- Speed up your RNN with Sequence Bucketing
- Better Batches with PyTorchText BucketIterator
- Tensorflow-esque bucket by sequence length
Freeze Embedding
Introduction
pre-trained language model을 fine-tuning하는 동안 embedding matrix를 고정하는 것은 간단합니다. transformers의 freezing embedding layer는 GPU memory를 절약할 수 있으므로 training할 때, 더 큰 batch size를 사용하는 동시에 training process 속도를 높일 수 있습니다.
Idea
-
이 아이디어의 이면에 있는 intuition은 embedding layer가 각 token의 독립적인 표현을 포함하고, 유사한 의미를 가진 token에 대한 vector가 추가 layer에서 매우 유사한 방식으로 사용되도록 pre-training 중에 embedding space에서 가깝도록 training되어야 한다는 것입니다. 하지만, label이 지정된 데이터의 양이 많지 않거나 실제 사용 사례에 일반적으로 사용되는 작은 corpus가 있는 경우, inference를 수행할 데이터에 train set에 표시되지 않은 일부 token이 포함될 수 있습니다. 이러한 새 token 중 일부는 label이 지정된 데이터에 synonym pair를 가질 수 있지만, gradient update는 language model에서 학습한 이러한 유형의 connection을 파괴할 수 있습니다.
-
다른 하나는 자체적으로 엄청난 수의 parameter를 포함하는 embedding matrix를 고정하기 때문에 gradient update가 발생하지 않아 계산 시간이 줄어들고 더 큰 batch size를 활용할 수 있습니다.
Splits Analysis
먼저, 다른 notebook에서 사용하던 KFold strategy를 사용하여 data를 분할하고 첫 번째 아이디어를 더 잘 이해하기 위해 몇 가지 분석을 수행합니다.
# !pip install -q matplotlib_venn
from itertools import chain
import numpy as np
import pandas as pd
from sklearn import model_selection
import matplotlib.pyplot as plt
from matplotlib_venn import venn2
%config InlineBackend.figure_format = "retina"
%matplotlib inline
train = pd.read_csv('train.csv', low_memory=False)
test = pd.read_csv('test.csv', low_memory=False)
roberta tokenizer를 사용하여 excerpts를 해당하는 input ids로 바꿔줍니다.
input_ids = (
f"{tokenizer.bos_token} " + train.excerpt + f" {tokenizer.eos_token}"
).apply(tokenizer.tokenize).apply(tokenizer.convert_tokens_to_ids).to_list()
train['input_ids'] = input_ids
random state 2021을 사용하여 5-Kfold split을 합니다
def create_folds(data, num_splits):
data["kfold"] = -1
kf = model_selection.KFold(n_splits=num_splits, shuffle=True, random_state=2021)
for fold, (train_index, valid_index) in enumerate(kf.split(X=data)):
data.loc[valid_index, "kfold"] = fold
return data
train = create_folds(train, num_splits=5)
각 fold에 대한 train 및 validation set token의 token overlap을 확인할 것입니다.
def create_features_targets(train, fold):
features_train = train[train.kfold!=fold]['input_ids'].tolist()
features_val = train[train.kfold==fold]['input_ids'].tolist()
targets_train = train[train.kfold!=fold]['target'].tolist()
targets_val = train[train.kfold==fold]['target'].tolist()
return features_train, targets_train, features_val, targets_val
# create train and validation features for each fold
features_train1, targets_train1, features_val1, targets_val1 = create_features_targets(train, 0)
features_train2, targets_train2, features_val2, targets_val2 = create_features_targets(train, 1)
features_train3, targets_train3, features_val3, targets_val3 = create_features_targets(train, 2)
features_train4, targets_train4, features_val4, targets_val4 = create_features_targets(train, 3)
features_train5, targets_train5, features_val5, targets_val5 = create_features_targets(train, 4)
# create set of unique input ids for each train and validation data
features_train1_set, features_val1_set = set(chain.from_iterable(features_train1)), set(chain.from_iterable(features_val1))
features_train2_set, features_val2_set = set(chain.from_iterable(features_train2)), set(chain.from_iterable(features_val2))
features_train3_set, features_val3_set = set(chain.from_iterable(features_train3)), set(chain.from_iterable(features_val3))
features_train4_set, features_val4_set = set(chain.from_iterable(features_train4)), set(chain.from_iterable(features_val4))
features_train5_set, features_val5_set = set(chain.from_iterable(features_train5)), set(chain.from_iterable(features_val5))
plt.figure(figsize=(12, 8))
plt.suptitle("Intersection of train tokens set and validation tokens set for each fold")
plt.subplot(231)
venn2(
[features_train1_set, features_val1_set],
set_labels=("Train", "Validation"),
set_colors=("blue", "plum")
)
plt.title('Fold 0')
plt.subplot(232)
venn2(
[features_train2_set, features_val2_set],
set_labels=("Train", "Validation"),
set_colors=("blue", "plum")
)
plt.title('Fold 1')
plt.subplot(233)
venn2(
[features_train3_set, features_val3_set],
set_labels=("Train", "Validation"),
set_colors=("blue", "plum")
)
plt.title('Fold 2')
plt.subplot(234)
venn2(
[features_train4_set, features_val4_set],
set_labels=("Train", "Validation"),
set_colors=("blue", "plum")
)
plt.title('Fold 3')
plt.subplot(235)
venn2(
[features_train5_set, features_val5_set],
set_labels=("Train", "Validation"),
set_colors=("blue", "plum")
)
plt.title('Fold 4')
plt.show()
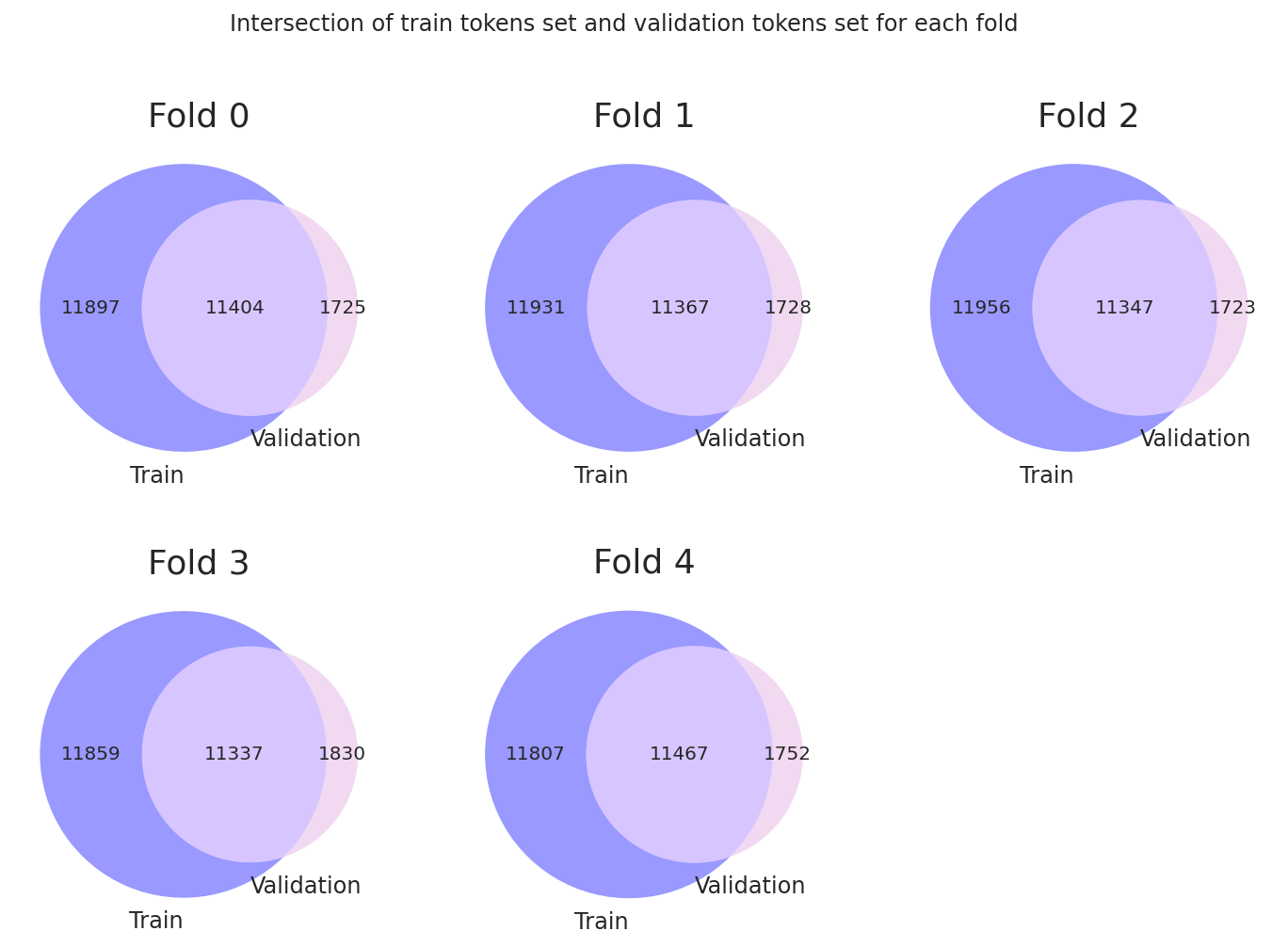
각 fold마다 unseen token의 수가 각 split에 대해 1700보다 큰 것을 볼 수 있습니다. 이는 train set보다 validation set에 unseen token이 많다는 것을 의미하며 이러한 경우, Freeze Embedding이 빛을 발합니다.
Implementation
여기에서 Freeze Embedding을 구현하는 방법을 살펴보겠습니다. 구현은 매우 간단하며 base model embedding을 고정하기만 하면 됩니다.
import transformers
from transformers import AutoConfig, AutoModelForSequenceClassification
freeze_embedding = True
_pretrained_model = "roberta-base"
config = AutoConfig.from_pretrained(_pretrained_model)
model = AutoModelForSequenceClassification.from_pretrained(_pretrained_model, config=config)
model.base_model.embeddings.requires_grad_(not freeze_embedding)
clear_output()
Conclusion
pre-trained language model, 특히 vocabulary가 많은 경우, embedding matrix를 고정하는 것이 좋습니다. 이는 엄청난 개선을 제공하지는 않지만, 일부 Kaggle competition에서 시도해 볼 수 있습니다.
이 setup은 freeze하지 않은 것과 동일하게 보이며 training 시간을 절약하고 매우 중요한 더 큰 batch size를 포함할 수 있습니다.
Resources and References
- Jigsaw Multilingual Toxic Comment Classification 10th Place Solution
- Semi-Frozen Embeddings for NLP Transfer Learning
- To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
- What Would Elsa Do? Freezing Layers During Transformer Fine-Tuning
Numeric Precision Reduction
Introduction
Numeric Precision Reduction은 floating point reduction과 quantization을 사용하여 속도를 높이는 것을 의미합니다. 이는 아마도 예측 시간 속도를 높이는 가장 일반적인 방법일 것입니다.
지난 몇 년 동안 GPU 하드웨어에서 float16 작업에 대한 support가 부족하다는 것은 weight과 activation의 precision을 줄이는 것이 종종 비생산적이라는 것을 의미했지만, Tensor core가 포함된 NVIDIA Volta와 Turing architecture의 도입은 최신 GPU가 이제 효율적인 float16 산술을 위해 잘 갖추어져 있음을 의미합니다.
Floating Point Representation
Floating point type은 sign, exponent, fraction이라는 세 가지 유형의 숫자 정보를 저장합니다. 전통적인 float32 표현에는 exponent와 fraction을 나타내는 각각 8비트와 23비트가 있습니다. 기존의 float16 표현(NVIDIA 하드웨어에 사용되는 형식)은 exponent와 fraction component를 대략 절반으로 줄입니다. TPU는 bfloat16이라는 variant를 사용합니다.
대부분의 transformer network는 accuracy penalty 없이 단순하게 float16 weight과 activation으로 변환할 수 있습니다.

network의 작은 부분, 특히 softmax 작업의 일부는 float32로 되어 있어야 합니다. 많은 수의 작은 값(our logits)의 합이 accumulated error의 원인이 될 수 있기 때문입니다. float16과 float32 값이 모두 사용되기 때문에 이 방법을 “mixed-precision” training이라고 합니다.
덜 정확한 숫자 표현은 두 가지 source에서 속도 향상을 가능하게 합니다.
- Native half-precision instructions
- 더 compact한 표현으로 인한 Larger batch sizes
How to Use?
Mixed precision은 주로 Tensor Core 지원 아키텍처(Volta, Turing, Ampere)에 이점이 있습니다. AMP는 이러한 아키텍처에서 상당한(2-3배) 속도 향상을 보여줍니다. 이전 아키텍처(Kepler, Maxwell, Pascal)에서는 약간의 속도 향상을 볼 수 있습니다. !nvidia-smi를 실행하여 GPU의 아키텍처를 표시할 수 있습니다.
-
NVIDIA-apex - NVIDIA는 floating point precision reduction과 관련된 다소 광범위한 benchmark 모음을 발표했습니다. 실제로 이 방법은 최대 3배의 속도 향상을 가져옵니다.
-
Torch - torch.cuda.amp - PyTorch 1.6 release에서 NVIDIA와 Facebook의 개발자는 mixed precision functionality를 AMP 패키지인 torch.cuda.amp로 PyTorch core로 옮겼습니다. torch.cuda.amp는 apex.amp에 비해 더 유연하고 직관적입니다.
Special Case
작은 batch가 포함된 dataset에서는 수행할 계산이 충분하지 않으면 예기치 않게 느린 학습으로 이어질 수 있으므로 mixed precision에 주의해야 합니다.
예를 들어, 이 competition dataset에서 Native AMP를 사용해 보았지만 결과가 개선되지 않았습니다. 그 이유는 아마도 overhead가 추가되고 대부분의 batch가 짧은 sequence로만 구성되기 때문에 그다지 도움이 되지 않기 때문일 것입니다. mixed precision은 큰 matrix 연산에 가장 도움이 됩니다.
Resources and References
-
[CommonLit Readability Prize - RoBERTa Torch FIT](https://www.kaggle.com/rhtsingh/commonlit-readability-prize-roberta-torch-fit) - 이를 구현한 FineTuning Notebook - Tips N Tricks # 8: Using automatic mixed precision training with PyTorch 1.6 - Abhishek’s YouTube Tutorial.
- NVIDIA Deep Learning Examples for Tensor Cores - Tons of state-of-the-Art Deep Learning examples.
- Torch AMP Examples
- Torch AMP Recipes
Gradient Accumulation
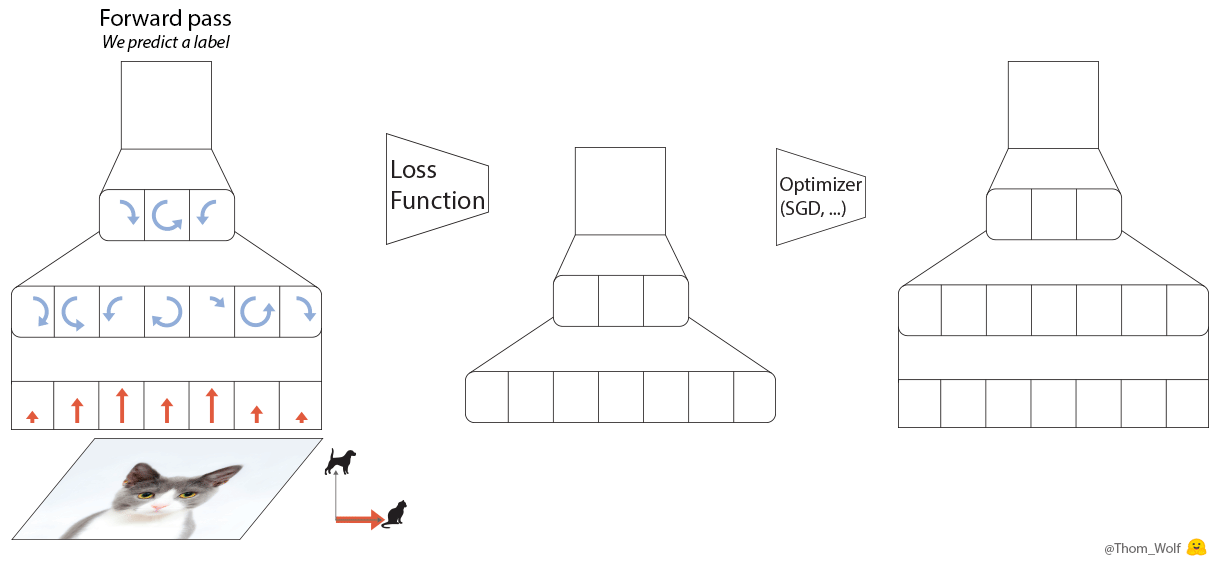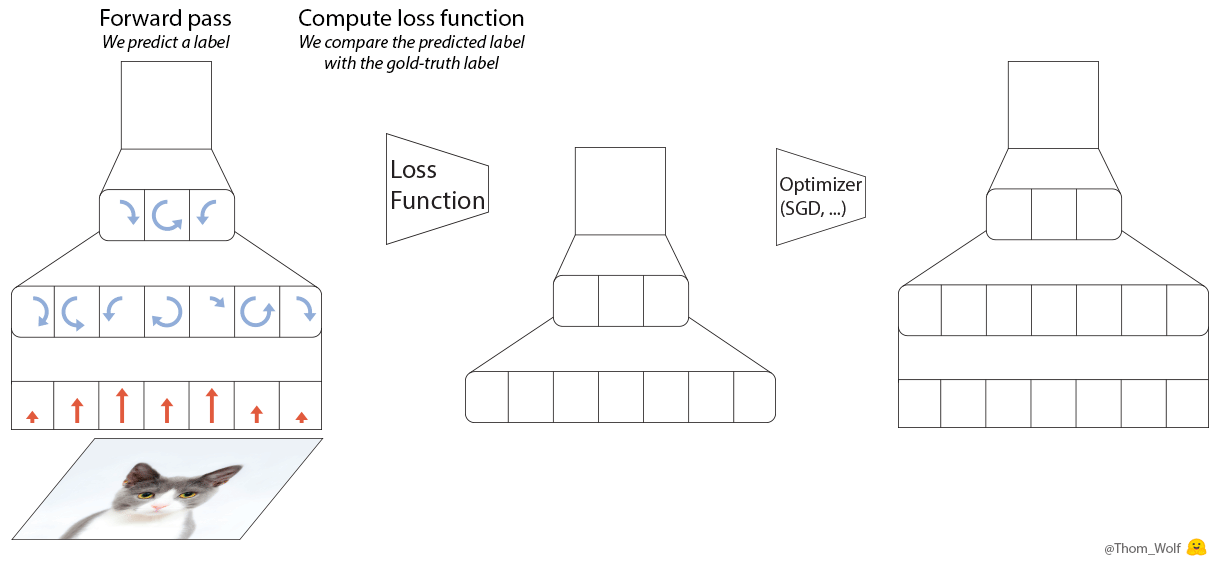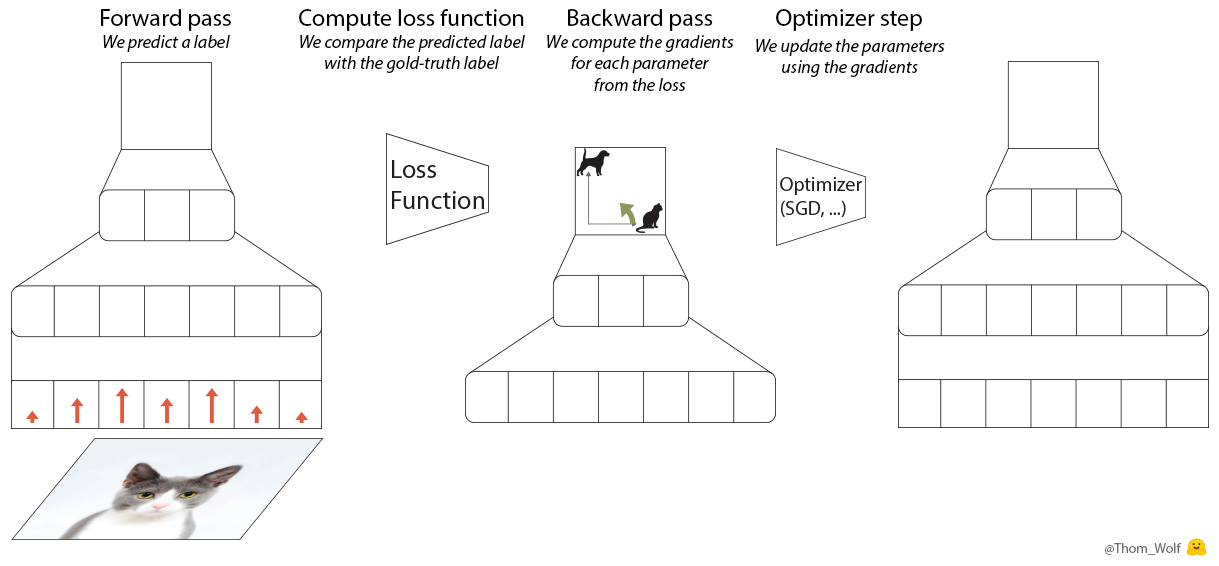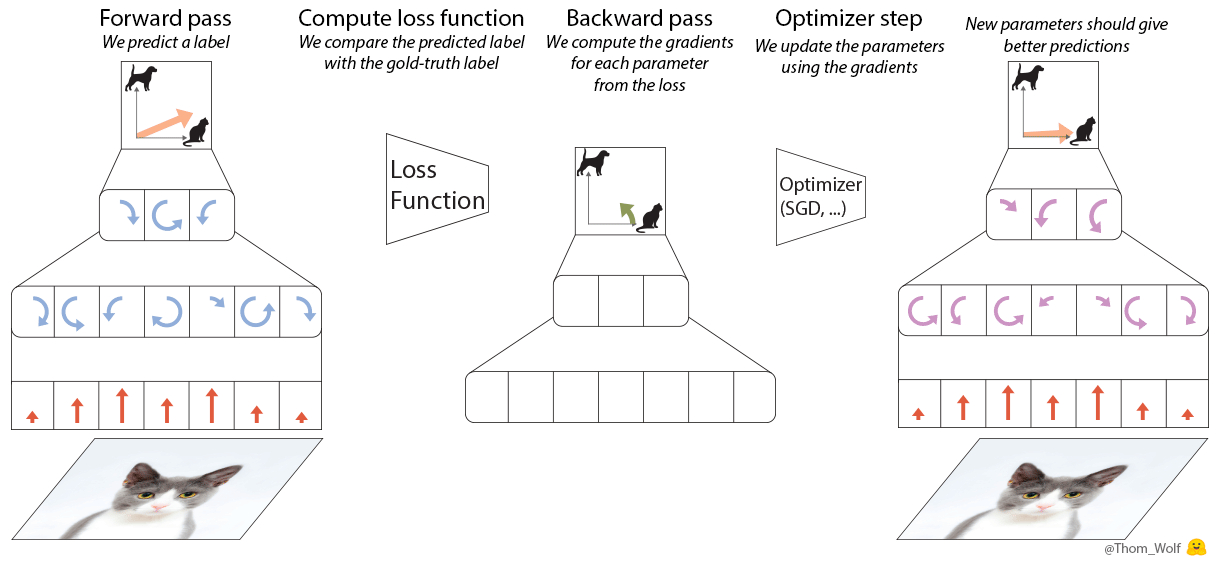
이 5단계에 해당하는 PyTorch 코드는 5줄로도 작성할 수 있습니다.
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = model(inputs) # Forward pass with new parameters
loss.backward() operation 중, 각 parameter(애니메이션에서 녹색)에 대해 gradient가 계산되고 각 parameter와 연결된 tensor에 저장됩니다: parameter.grad(애니메이션의 중간 그래프).
Introduction
Gradient Accumulation은 gradient descent 단계를 수행하기 위해 optimizer.step()을 호출하기 전에 parameter.grad tensor에서 여러 backward operation의 gradient를 합산한다는 것을 의미합니다.
이는 우리가 model.zero_grad() 또는 optimizer.zero_grad()를 호출하지 않는 한 gradient tensor가 재설정되지 않기 때문에 PyTorch에서 간단하게 수행할 수 있습니다.
loss가 training sample에 대한 평균인 경우 accumulation step으로 나누어야 합니다.
Implementation
Gradient accumulation 부분을 코딩하는 것도 PyTorch에서는 엄청나게 쉽습니다. 각 batch에서 loss를 저장한 다음 선택한 batch 수 이후에만 model parameter를 업데이트하기만 하면 됩니다.
우리는 accumulation_steps 즉, batch 수에 대해 parameter를 업데이트하는 optimizer.step()을 유지합니다. 또한, model.zero_grad()가 동시에 호출되어 accumulated gradient를 재설정합니다.
다음은 gradient accumulation을 사용하여 모델을 training하는 간단한 방법입니다.
optimizer.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
optimizer.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
Resources and References
-
[CommonLit Readability Prize - RoBERTa Torch ITPT](https://www.kaggle.com/rhtsingh/commonlit-readability-prize-roberta-torch-itpt) - Pretraining Kernel of mine specific to this comptition implements Accumulated Gradients. - HugginFace Examples - The official repository of HuggingFace Examples which implements Gradient Accumulation in all PyTorch scripts.
- Gradient Accumulation: Overcoming Memory Constraints in Deep Learning
- Gradient Accumulation in TensorFlow
Gradient Checkpointing
Introduction
Gradient Checkpointing은 계산 시간이 약간 증가하는 cost로 deep neural network를 training할 때, memory footprint를 줄이는 데 사용되는 방법입니다.memory에 대한 compute를 trading할 수 있으므로 더 큰 모델을 training하고 큰 minibatch size를 사용할 수 있습니다.
Idea
아이디어는 모델을 따라 작은 chunk로 gradient를 back-propagate하여 전체 back propagation graph를 저장하는 데 필요한 메모리를 각 chunk와 관련된 partial forward pass의 추가 compute와 trading하는 것입니다.
이는 메모리 요구 사항을 줄이기 위해 추가 computing을 추가하기 때문에 다소 느린 방법이지만 더 큰 batch size를 선택하는 데 도움이 되며 일부 setting에서는 흥미로울 수 있습니다.
References and Resources
- Official Paper - Training Deep Nets with Sublinear Memory Cost
- PyTorch Doc - torch.utils.checkpoint.checkpoint
- PyTorch Memory optimizations via gradient checkpointing - pytorch_memonger
- TensorFlow - OpenAI Gradient Checkpointing
- PyTorch Checkpoint
- Training Neural Nets on Larger Batches
Ending Notes
-
더 많은 optimization strategy(특히 multi-GPU setup에서)가 있지만, 이 방법이 가장 영향력 있는 strategy이라는 것을 발견했습니다.
-
추가 research로 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models와 하드웨어가 이전에 가능하다고 생각했던 것보다 훨씬 더 많은 작업을 수행할 수 있는 방법에 대한 수많은 새로운 아이디어가 포함된 후속 paper를 탐색할 수 있습니다. 이 paper에서 설명하는 기술은 나중에 HuggingFace v4.2.0에 통합된 라이브러리인 DeepSpeed와 FairScale에서 구현됩니다.
-
HuggingFace는 최근 distributed training과 mixed precision에 대한 simplicity과 support를 제공하는 Accelerate를 도입했습니다.
-
다양한 task를 위한 transformers 학습 및 구현을 위한 보다 포괄적인 repository는 여기, 여기 그리고 여기에서 찾을 수 있습니다.
원문
https://www.kaggle.com/code/rhtsingh/speeding-up-transformer-w-optimization-strategies/notebook
댓글남기기