[Feedback Prize - English Language Learning] SWA, Apex AMP & Interpreting Transformers in Torch
SWA-LP & Interpreting Transformer Interactively
Introduction
SWA-LP는 low precision training을 위한 Stochastic Weight Averaging의 약자입니다. SWA-LP는 모든 숫자가 8비트로 양자화된 경우에도 full-precision training의 성능과 일치할 수 있습니다.
이 notebook은 PyTorch를 사용하는 transformers에서 NVIDIA Apex를 사용하여 Stochastic Weight Averaging technique를 구현한 것입니다. notebook은 또한 NLP model 이해를 위한 platform LIT(Language Interpretability Tool)를 사용하여 Transformers를 해석하는 방법을 구현합니다.
Idea
이 커널은 SWA 및 Apex AMP를 사용하여 Transformers를 Fine-tuning하는 방법을 설명합니다. 또한 Weighted Layer Pooling, MADGRAD Optimizer, Grouped LLRD 등과 같은 다양한 전략을 연결하는 방법을 보여줍니다.
또한, transformer model 해석을 위한 metrics, embedding spaces 및 flexible slicing을 포함한 aggregate analysis뿐만 아니라 salience map, attention을 위한 시각화를 구현하는 방법도 볼 것입니다.
Overview
코드로 넘어가기 전에 몇 가지 기술과 작동 방식을 이해합시다. 각 기술 뒤에 높은 수준의 idea가 있으면 코드를 더 잘 이해하는 데 도움이 됩니다.
Stochastic Weight Averaging
Paper: Averaging Weights Leads to Wider Optima and Better Generalization
Blog: PyTorch 1.6 now includes Stochastic Weight Averaging
SWA는 여러 training 단계에서 동일한 network의 weight을 결합하여 ensemble을 생성한 다음, 이 모델을 combined weight와 함께 사용하여 예측합니다.
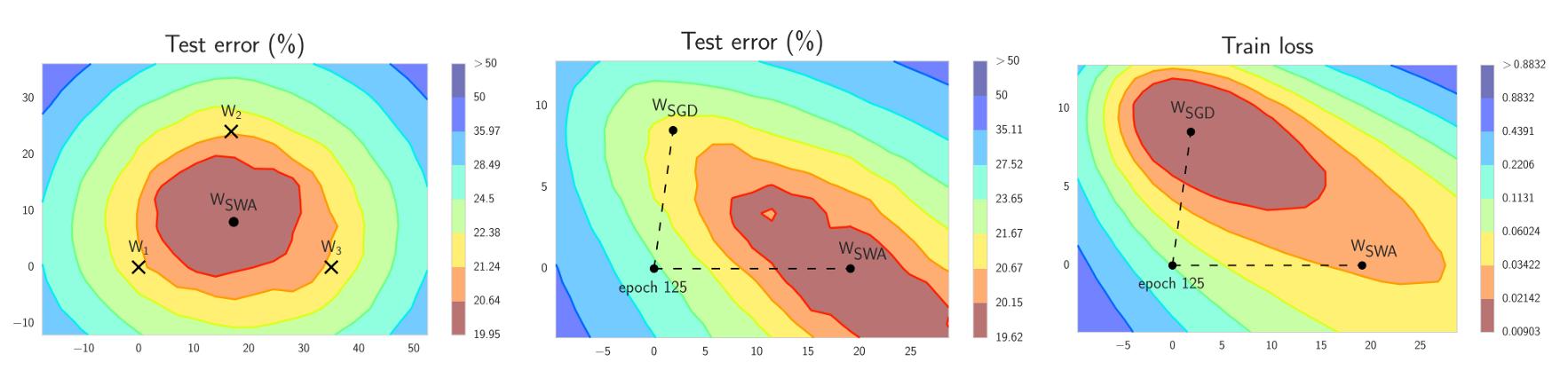
여기에는 SWA가 작동하도록 하는 두 가지 중요한 요소가 있습니다.
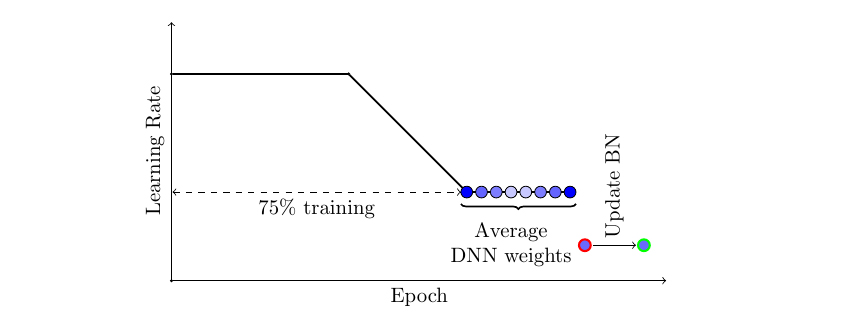
- 첫번째, SWA는 modified learning rate schedule을 사용하여 SGD(또는 Adam과 같은 다른 optimizer)가 단순히 단일 solution으로 수렴하는 대신 optimum에 대해 생각하며 다양한 model을 탐색하도록 합니다. 예를 들어, training 시간의 처음 75%에 대해 standard decaying learning rate 전략을 사용한 다음 나머지 25% 시간 동안 learning rate을 합리적으로 높은 constant value로 설정할 수 있습니다(아래 그림 참조).
-
두 번째 요소는 SGD가 통과하는 network의 weight(일반적으로 동일한 평균)의 평균을 취하는 것입니다. 예를 들어, training 시간의 마지막 25% 내에서 모든 epoch가 끝날 때 얻은 weight의 running average를 유지할 수 있습니다. training이 완료되면, network의 weight을 계산된 SWA 평균으로 설정합니다.
-
또 다른 중요한 세부 사항은 batch normalization입니다. batch normalization layer는 training 중 activation의 running staistics를 계산합니다. weight의 SWA 평균은 training 중 예측에 사용되지 않습니다. 따라서, batch normalization layer에는 training이 끝날 때 계산된 activation statistics가 없습니다. SWA model을 사용하여 train data에 대해 하나의 forward pass를 수행하여 이러한 statistics를 계산할 수 있습니다.

따라서, 우리는 하나의 model만 training하고, training하는 동안 두 개의 model을 메모리에 저장하면 됩니다. 예측을 위해서는 running average model만 필요합니다.
MADGRAD Optimizer
MADGRAD는 AdaGrad adaptive gradient methods에 속하는 새로운 optimization 방법입니다. MADGRAD는 vision의 classification과 image-to-image task, natural language processing의 recurrent와 bidirectionally-masked model을 포함하여 여러 분야의 deep learning optimization 문제에서 우수한 성능을 보여줍니다.
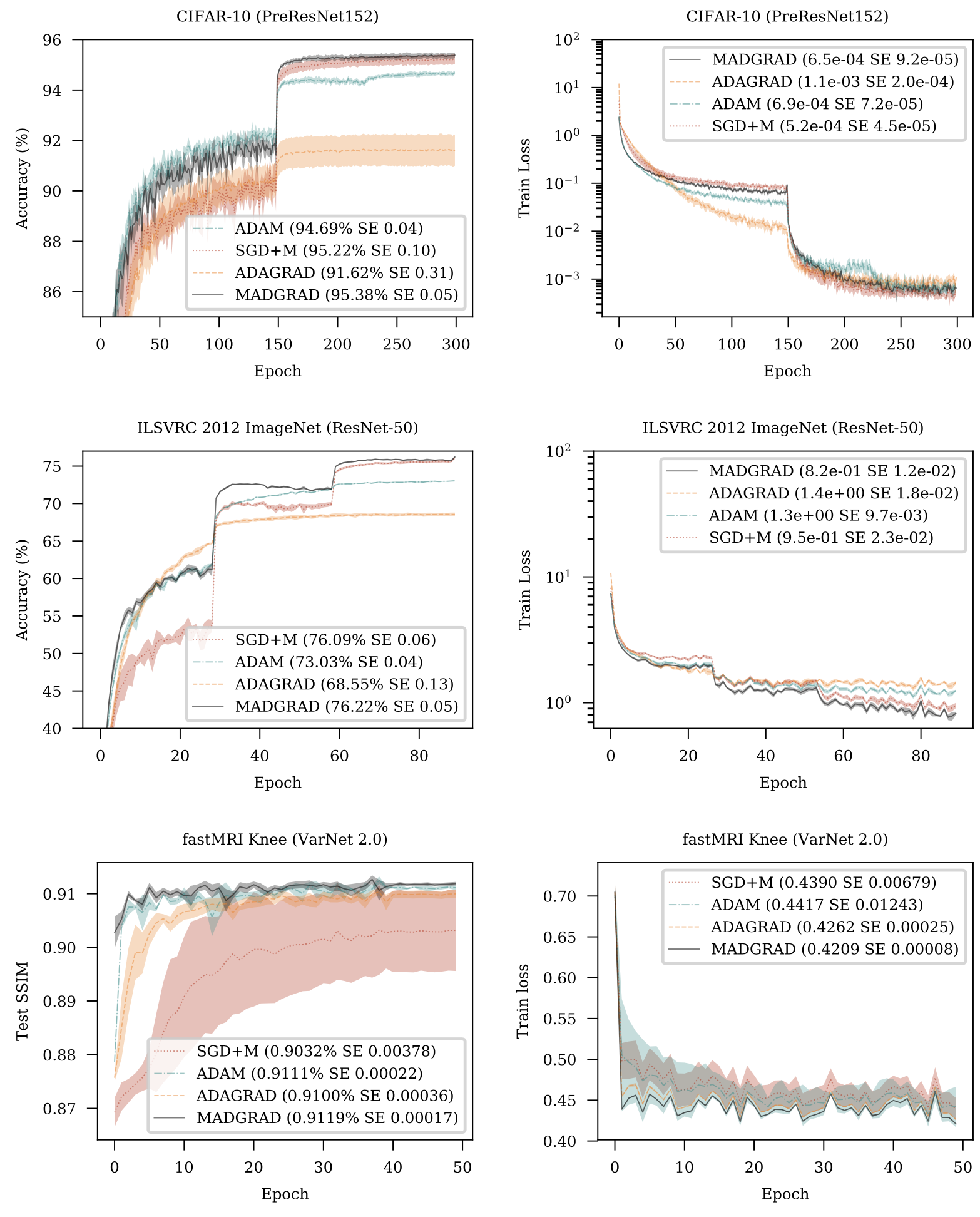
이러한 각 task에 대해 MADGRAD는 adaptive method가 일반적으로 성능이 좋지 않다는 문제에도 불구하고, test set 성능에서 SGD 및 ADAM과 일치하거나 능가합니다.
Things to Note
-
익숙한 것보다 더 낮은 weight decay를 사용해야 할 수도 있습니다. (자주 0)
-
최적의 learning rate은 SGD 또는 Adam과 다르기 때문에 full learning rate sweep을 수행해야 합니다. NLP model에서는 gradient clipping도 도움이 되었습니다.
Language Interpretability Tool (LIT)
Paper: The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models
Blog: The Language Interpretability Tool (LIT): Interactive Exploration and Analysis of NLP Models
Official Page: Language Interpretability Tool
Examples: GitHub
LIT는 NLP 모델의 시각화 및 이해를 위한 오픈 소스 플랫폼입니다. LIT에는 많은 기본 제공 기능이 포함되어 있지만, custom interpretability techniques, metrics calculations, counterfactual generators, visualizations 등을 추가하는 기능을 사용하여 사용자 정의를 할 수도 있습니다.
| Built-in capabilities | Supported task types | Framework agnostic |
|---|---|---|
| Salience maps | Classification | TensorFlow 1.x |
| Attention visualization | Regression | TensorFlow 2.x |
| Metrics calculations | Text generation / seq2seq | PyTorch |
| Counterfactual generation | Masked language models | Notebook compatibility |
| Model and datapoint comparison | Span labeling | Custom inference code |
| Embedding visualization | Multi-headed models | Remote Procedure Calls |
| And more… | And more… | And more… |
LIT는 서버로 실행하거나 Colab 및 Jupyter와 같은 python 노트북 환경 내부에서 실행할 수 있습니다.
NVIDIA Apex - AMP
- In Speeding up Transformer w/ Optimization Strategies notebook.
Weighted Layers Pooling
- In Utilizing Transformer Representations Efficiently notebook. - 글 작성 후, 링크 달기
Grouped Layerwise Learning Rate Decay
- In Guide to HuggingFace Schedulers & Differential LRs notebook. - 글 작성 후, 링크 달기
Code
Install Dependencies
먼저 필요한 설정을 하겠습니다. NVIDIA Apex API, MADGRAD Optimizer 및 Language Interpretability Tool을 설치할 것입니다. 아래에서 Kaggle과 Google Colab에 대한 예비 설정 명령을 찾을 수 있습니다.
NOTE: Google Colab을 사용하는 경우 계정에서 새 API token을 생성하여 kaggle.json을 다운로드해야 합니다.
Colab Setup
from google.colab import files
files.upload() # Upload your Kaggle API Token
!mkdir ~/.kaggle
!mv kaggle.json ~/.kaggle
!chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions download -c commonlitreadabilityprize
!unzip commonlitreadabilityprize.zip
# !unzip train.csv.zip
<input type="file" id="files-a624ac2f-fa7c-48e9-a0eb-238d51e2978f" name="files[]" multiple disabled
style="border:none" />
<output id="result-a624ac2f-fa7c-48e9-a0eb-238d51e2978f">
Upload widget is only available when the cell has been executed in the
current browser session. Please rerun this cell to enable.
</output>
<script>// Copyright 2017 Google LLC // // Licensed under the Apache License, Version 2.0 (the "License"); // you may not use this file except in compliance with the License. // You may obtain a copy of the License at // // http://www.apache.org/licenses/LICENSE-2.0 // // Unless required by applicable law or agreed to in writing, software // distributed under the License is distributed on an "AS IS" BASIS, // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. // See the License for the specific language governing permissions and // limitations under the License.
Saving kaggle.json to kaggle.json
Downloading commonlitreadabilityprize.zip to /content
0% 0.00/1.13M [00:00<?, ?B/s]
100% 1.13M/1.13M [00:00<00:00, 156MB/s]
Archive: commonlitreadabilityprize.zip
inflating: sample_submission.csv
inflating: test.csv
inflating: train.csv
%%writefile setup.sh
export CUDA_HOME=/usr/local/cuda-10.1
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir ./
Writing setup.sh
%%capture
!sh setup.sh
!pip -q install madgrad
!pip -q install lit_nlp
!pip -q install transformers
Kaggle Setup
# %%writefile setup.sh
# git clone https://github.com/NVIDIA/apex
# cd apex
# pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
# rm -rf ./apex
# %%capture
# !sh setup.sh
# !pip -q install madgrad
# !pip -q install lit_nlp
Import Dependencies
여기에서는 필요한 dependency과 몇 가지 utility function을 가져올 것입니다. Optimal_num_of_loader_workers는 dataloader에 대한 최적의 worker 수를 찾고 fix_all_seeds는 reproducibility 작업을 수행합니다.
import os
import gc
gc.enable()
import math
import json
import time
import random
import multiprocessing
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
import numpy as np
import pandas as pd
from tqdm import tqdm, trange
from sklearn import model_selection
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Parameter
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, SequentialSampler, RandomSampler
try:
from apex import amp
APEX_INSTALLED = True
except ImportError:
APEX_INSTALLED = False
from madgrad import MADGRAD
try:
from torch.optim.swa_utils import AveragedModel, update_bn, SWALR
SWA_AVAILABLE = True
except ImportError:
SWA_AVAILABLE = False
import transformers
from transformers import (
WEIGHTS_NAME,
AdamW,
AutoConfig,
AutoModel,
AutoTokenizer,
get_cosine_schedule_with_warmup,
logging,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
)
logging.set_verbosity_warning()
logging.set_verbosity_error()
def fix_all_seeds(seed):
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def optimal_num_of_loader_workers():
num_cpus = multiprocessing.cpu_count()
num_gpus = torch.cuda.device_count()
optimal_value = min(num_cpus, num_gpus*4) if num_gpus else num_cpus - 1
return optimal_value
print(f"Apex AMP Installed :: {APEX_INSTALLED}")
print(f"SWA Available :: {SWA_AVAILABLE}")
MODEL_CONFIG_CLASSES = list(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING.keys()) # 모델별 configuration
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES) # 모델 이름
Apex AMP Installed :: False
SWA Available :: True
Data & Train-Validation Split
여기에서 데이터를 로드하고 random_state=2021 5-KFold split을 사용할 것입니다.
train = pd.read_csv('train.csv', low_memory=False)
def create_folds(data, num_splits):
data["kfold"] = -1
kf = model_selection.KFold(n_splits=num_splits, shuffle=True, random_state=2021)
for f, (t_, v_) in enumerate(kf.split(X=data)):
data.loc[v_, 'kfold'] = f
return data
train = create_folds(train, num_splits=5)
Training Config
Config class는 training hyperparameter, output path 등을 정의합니다. 여기서는 model, tokenizer, optimizer, scheduler, swa 및 training configuration을 정의합니다.
class Config:
# model
num_labels = 1
model_type = 'roberta'
model_name_or_path = 'roberta-base'
config_name = 'roberta-base'
fp16 = True if APEX_INSTALLED else False
fp16_opt_level = "O1"
# tokenizer
tokenizer_name = 'roberta-base'
max_seq_length = 128
# train
epochs = 10
train_batch_size = 4
eval_batch_size = 4
# optimizer
optimizer_type = 'MADGRAD'
learning_rate = 2e-5
weight_decay = 1e-5
epsilon = 1e-6
max_grad_norm = 1.0
# stochastic weight averaging
swa = True
swa_start = 7
swa_learning_rate = 1e-4
anneal_epochs=3
anneal_strategy='cos'
# scheduler
decay_name = 'cosine-warmup'
warmup_ratio = 0.03
# logging
logging_steps = 10
# evaluate
output_dir = 'output'
seed = 2021
Average Meter
metrics를 기록하는 데 도움이 됩니다.
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
self.max = 0
self.min = 1e5
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
if val > self.max:
self.max = val
if val < self.min:
self.min = val
Dataset Retriever
Dataset Retriever는 sample과 해당 label을 저장합니다. 호출되면 sample이 input_ids, attention_mask, 그리고 모델 입력을 위한 텐서로의 covert로 처리됩니다.
class DatasetRetriever(Dataset):
def __init__(self, data, tokenizer, max_len, is_test=False):
super().__init__()
self.data = data
self.is_test = is_test
self.excerpts = self.data.excerpt.values.tolist()
if not self.is_test:
self.targets = self.data.target.values.tolist()
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.data)
def __getitem__(self, item):
excerpt = self.excerpts[item]
features = self.convert_examples_to_features(excerpt, self.tokenizer, self.max_len)
features = {key: torch.tensor(value, dtype=torch.long) for key, value in features.items()}
if not self.is_test:
label = self.targets[item]
features["labels"] = torch.tensor(label, dtype=torch.double)
return features
def convert_examples_to_features(self, example, tokenizer, max_len):
# encode_plus => encoding된 sequence 외에 추가 정보를 담고 있습니다: the mask for sequence classification and the overflowing elements if a max_length is specified.
features = tokenizer.encode_plus(
example.replace("\n", ""),
max_length=max_len,
padding="max_length",truncation=True,
return_attention_mask=True
)
return features
Model
여기에서 model을 정의합니다. 이 model은 각 layer의 cls embedding에 대한 weighted layer pooling, multi-sample dropout, 다른 커널에서 설명한 layer initialization 전략을 사용합니다.
class Model(nn.Module):
def __init__(self, model_name, config):
super().__init__()
self.config = config
self.roberta = AutoModel.from_pretrained(model_name, config=config)
self.dropout = nn.Dropout(p=0.2)
self.high_dropout = nn.Dropout(p=0.5)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-5)
self._init_weights(self.layer_norm)
self.regressor = nn.Linear(config.hidden_size, config.num_labels)
self._init_weights(self.regressor)
weights_init = torch.zeros(config.num_hidden_layers + 1).float()
# tensor([-3., -3., -3., -3., -3., -3., -3., -3., -3., -3., -3., -3., 0.])
weights_init.data[:-1] = -3
self.layer_weights = torch.nn.Parameter(weights_init)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def forward(self, input_ids=None, attention_mask=None, labels=None):
outputs = self.roberta(input_ids, attention_mask=attention_mask)
all_hidden_states = outputs[2]
# weighted layer pooling
# layer: torch.Size([24, 250, 768])
# layer[:, 0]: torch.Size([24, 768])
# cls_embeddings: torch.Size([24, 768, 13])
cls_embeddings = torch.stack([self.dropout(layer[:, 0]) for layer in all_hidden_states],
dim=2)
# self.layer_weights: torch.Size([13])
cls_output = (torch.softmax(self.layer_weights, dim=0) * cls_embeddings).sum(-1)
# cls_output: torch.Size([24, 768])
cls_output = self.layer_norm(cls_output)
# multi-sample dropout
# logits: torch.Size([4, 1])
logits = torch.mean(
torch.stack(
[self.regressor(self.high_dropout(cls_output)) for _ in range(5)],
dim=0
),
dim=0
)
# calculate loss
loss = None
if labels is not None:
loss_fn = torch.nn.MSELoss()
logits = logits.view(-1).to(labels.dtype)
loss = torch.sqrt(loss_fn(logits, labels.view(-1)))
output = (logits,) + outputs[2:]
del all_hidden_states, cls_embeddings
del cls_output, logits
gc.collect()
return ((loss,) + output) if loss is not None else output
Grouped Optimizer Parameters & LLRD
실험에서 단순한 LLRD보다 더 나은 성능과 generalization을 보여주기 때문에 우리는 Grouped-LLRD(Layer Wise Learning Rate Decay)를 사용할 것입니다.
def get_optimizer_grouped_parameters(args, model):
no_decay = ["bias", "LayerNorm.weight"]
group1=['layer.0.','layer.1.','layer.2.','layer.3.']
group2=['layer.4.','layer.5.','layer.6.','layer.7.']
group3=['layer.8.','layer.9.','layer.10.','layer.11.']
group_all=['layer.0.','layer.1.','layer.2.','layer.3.','layer.4.','layer.5.','layer.6.','layer.7.','layer.8.','layer.9.','layer.10.','layer.11.']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.roberta.named_parameters() if not any(nd in n for nd in no_decay) and not any(nd in n for nd in group_all)],'weight_decay': args.weight_decay},
{'params': [p for n, p in model.roberta.named_parameters() if not any(nd in n for nd in no_decay) and any(nd in n for nd in group1)],'weight_decay': args.weight_decay, 'lr': args.learning_rate/2.6},
{'params': [p for n, p in model.roberta.named_parameters() if not any(nd in n for nd in no_decay) and any(nd in n for nd in group2)],'weight_decay': args.weight_decay, 'lr': args.learning_rate},
{'params': [p for n, p in model.roberta.named_parameters() if not any(nd in n for nd in no_decay) and any(nd in n for nd in group3)],'weight_decay': args.weight_decay, 'lr': args.learning_rate*2.6},
{'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and not any(nd in n for nd in group_all)],'weight_decay': 0.0},
{'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and any(nd in n for nd in group1)],'weight_decay': 0.0, 'lr': args.learning_rate/2.6},
{'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and any(nd in n for nd in group2)],'weight_decay': 0.0, 'lr': args.learning_rate},
{'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and any(nd in n for nd in group3)],'weight_decay': 0.0, 'lr': args.learning_rate*2.6},
{'params': [p for n, p in model.named_parameters() if args.model_type not in n], 'lr':args.learning_rate*20, "weight_decay": 0.0},
]
return optimizer_grouped_parameters
Utilities
아래의 코드는 다른 component를 초기화하는 utility function을 정의합니다.
def make_model(args, output_attentions=False):
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name)
config = AutoConfig.from_pretrained(args.config_name)
config.update({"num_labels": args.num_labels})
config.update({"output_hidden_states": True})
if output_attentions:
config.update({"output_attentions": True})
model = Model(args.model_name_or_path, config=config)
return model, config, tokenizer
def make_optimizer(args, model):
optimizer_grouped_parameters = get_optimizer_grouped_parameters(args, model)
if args.optimizer_type == "AdamW":
optimizer = AdamW(
optimizer_grouped_parameters,
lr=args.learning_rate,
eps=args.epsilon,
correct_bias=not args.use_bertadam
)
else:
optimizer = MADGRAD(
optimizer_grouped_parameters,
lr=args.learning_rate,
eps=args.epsilon,
weight_decay=args.weight_decay
)
return optimizer
def make_scheduler(args, optimizer, num_warmup_steps, num_training_steps):
if args.decay_name == "cosine-warmup":
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps
)
else:
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps
)
return scheduler
def make_loader(args, data, tokenizer, fold):
train_set, valid_set = data[data["kfold"] != fold], data[data["kfold"] == fold]
train_dataset = DatasetRetriever(train_set, tokenizer, args.max_seq_length)
valid_dataset = DatasetRetriever(valid_set, tokenizer, args.max_seq_length)
print(f"Num examples Train= {len(train_dataset)}, Num examples Valid={len(valid_dataset)}")
train_sampler = RandomSampler(train_dataset)
valid_sampler = SequentialSampler(valid_dataset)
train_dataloader = DataLoader(
train_dataset,
batch_size=args.train_batch_size,
sampler=train_sampler,
num_workers=optimal_num_of_loader_workers(),
pin_memory=True,
drop_last=False
)
valid_dataloader = DataLoader(
valid_dataset,
batch_size=args.eval_batch_size,
sampler=valid_sampler,
num_workers=optimal_num_of_loader_workers(),
pin_memory=True,
drop_last=False
)
return train_dataloader, valid_dataloader
Trainer
여기서 우리는 main engine이 될 Trainer class를 정의합니다. 아래에서는 swa 및 apex-amp를 사용해 training support에 필요한 변경을 수행합니다.
class Trainer:
def __init__(
self, model, tokenizer,
optimizer, scheduler,
swa_model=None, swa_scheduler=None
):
self.model = model
self.tokenizer = tokenizer
self.optimizer = optimizer
self.scheduler = scheduler
self.swa_model = swa_model
self.swa_scheduler = swa_scheduler
def train(self, args, train_dataloader, epoch, result_dict):
count = 0
losses = AverageMeter()
self.model.zero_grad()
self.model.train()
fix_all_seeds(args.seed)
for batch_idx, batch_data in enumerate(train_dataloader):
input_ids, attention_mask, labels = batch_data['input_ids'], batch_data['attention_mask'], batch_data['labels']
input_ids, attention_mask, labels = input_ids.cuda(), attention_mask.cuda(), labels.cuda()
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss, logits = outputs[:2]
if args.fp16:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
count += labels.size(0)
losses.update(loss.item(), input_ids.size(0))
if args.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(self.optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), args.max_grad_norm)
self.optimizer.step()
if not args.swa:
self.scheduler.step()
else:
if (epoch+1) < args.swa_start:
self.scheduler.step()
self.optimizer.zero_grad()
if (batch_idx % args.logging_steps == 0) or (batch_idx+1)==len(train_dataloader):
_s = str(len(str(len(train_dataloader.sampler))))
ret = [
('Epoch: {:0>2} [{: >' + _s + '}/{} ({: >3.0f}%)]').format(epoch, count, len(train_dataloader.sampler), 100 * count / len(train_dataloader.sampler)),
'Train Loss: {: >4.5f}'.format(losses.avg),
]
print(', '.join(ret))
if args.swa and (epoch+1) >= args.swa_start:
self.swa_model.update_parameters(self.model)
self.swa_scheduler.step()
result_dict['train_loss'].append(losses.avg)
return result_dict
Evaluator
여기에서 model 성능을 평가하고 결과를 저장하는 데 사용할 Evaluator class를 정의합니다.
Note: 두 가지 evaluate function이 있습니다. 첫 번째는 원래 모델로 평가하기 위한 것이고 두 번째는 training이 완료된 후, swa_model로 평가하기 위한 것입니다.
class Evaluator:
def __init__(self, model, swa_model):
self.model = model
self.swa_model = swa_model
def save(self, result, output_dir):
with open(f'{output_dir}/result_dict.json', 'w') as f:
f.write(json.dumps(result, sort_keys=True, indent=4, ensure_ascii=False))
def evaluate(self, valid_dataloader, epoch, result_dict):
losses = AverageMeter()
for batch_idx, batch_data in enumerate(valid_dataloader):
self.model = self.model.eval()
input_ids, attention_mask, labels = batch_data['input_ids'], batch_data['attention_mask'], batch_data['labels']
input_ids, attention_mask, labels = input_ids.cuda(), attention_mask.cuda(), labels.cuda()
with torch.no_grad():
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss, logits = outputs[:2]
losses.update(loss.item(), input_ids.size(0))
print('----Validation Results Summary----')
print('Epoch: [{}] Valid Loss: {: >4.5f}'.format(epoch, losses.avg))
result_dict['val_loss'].append(losses.avg)
return result_dict
def swa_evaluate(self, valid_dataloader, epoch, result_dict):
losses = AverageMeter()
for batch_idx, batch_data in enumerate(valid_dataloader):
self.swa_model = self.swa_model.eval()
input_ids, attention_mask, labels = batch_data['input_ids'], batch_data['attention_mask'], batch_data['labels']
input_ids, attention_mask, labels = input_ids.cuda(), attention_mask.cuda(), labels.cuda()
with torch.no_grad():
outputs = self.swa_model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss, logits = outputs[:2]
losses.update(loss.item(), input_ids.size(0))
print('----SWA Validation Results Summary----')
print('Epoch: [{}] Valid Loss: {: >4.5f}'.format(epoch, losses.avg))
result_dict['swa_loss'].append(losses.avg)
return result_dict
Initialize Training
아래 방법을 사용하여 모든 training component를 초기화합니다. model, scheduler, optimizer, train 및 eval loader, mixed precision training, swa 및 결 results dict을 초기화하는 데 도움이 됩니다.
def init_training(args, data, fold):
fix_all_seeds(args.seed)
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
# model
model, model_config, tokenizer = make_model(args)
if torch.cuda.device_count() >= 1:
print('Model pushed to {} GPU(s), type {}.'.format(
torch.cuda.device_count(),
torch.cuda.get_device_name(0))
)
model = model.cuda()
else:
raise ValueError('CPU training is not supported')
train_dataloader, valid_dataloader = make_loader(args, data, tokenizer, fold)
optimizer = make_optimizer(args, model)
# scheduler
num_training_steps = len(train_dataloader) * args.epochs
if args.warmup_ratio > 0:
num_warmup_steps = int(args.warmup_ratio * num_training_steps)
else:
num_warmup_steps = 0
print(f"Total Training Steps: {num_training_steps}, Total Warmup Steps: {num_warmup_steps}")
scheduler = make_scheduler(args, optimizer, num_warmup_steps, num_training_steps)
# stochastic weight averaging
swa_model = AveragedModel(model)
swa_scheduler = SWALR(
optimizer, swa_lr=args.swa_learning_rate,
anneal_epochs=args.anneal_epochs,
anneal_strategy=args.anneal_strategy
)
print(f"Total Training Steps: {num_training_steps}, Total Warmup Steps: {num_warmup_steps}, SWA Start Step: {args.swa_start}")
# mixed precision training with NVIDIA Apex
if args.fp16:
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
result_dict = {
'epoch':[],
'train_loss': [],
'val_loss' : [],
'swa_loss': [],
'best_val_loss': np.inf
}
return (
model, model_config, tokenizer, optimizer, scheduler,
train_dataloader, valid_dataloader, result_dict,
swa_model, swa_scheduler
)
Run
training, evaluation, best model, swa model에 대한 bn 업데이트 등과 같은 모든 것을 함께 연결하는 main function입니다.
Note: Kaggle과 Colab에서 제공한 Tesla P100-PCIE-16GB에서 training을 완료하기 까지 1시간이 걸립니다.
def run(data, fold):
args = Config()
model, model_config, tokenizer, optimizer, scheduler, train_dataloader, \
valid_dataloader, result_dict, swa_model, swa_scheduler = init_training(args, data, fold)
trainer = Trainer(model, tokenizer, optimizer, scheduler, swa_model, swa_scheduler)
evaluator = Evaluator(model, swa_model)
train_time_list = []
valid_time_list = []
for epoch in range(args.epochs):
result_dict['epoch'].append(epoch)
# Train
torch.cuda.synchronize()
tic1 = time.time()
result_dict = trainer.train(
args, train_dataloader,
epoch, result_dict
)
torch.cuda.synchronize()
tic2 = time.time()
train_time_list.append(tic2 - tic1)
# Evaluate
torch.cuda.synchronize()
tic3 = time.time()
result_dict = evaluator.evaluate(
valid_dataloader, epoch, result_dict
)
torch.cuda.synchronize()
tic4 = time.time()
valid_time_list.append(tic4 - tic3)
output_dir = os.path.join(args.output_dir, f"checkpoint-fold-{fold}")
if result_dict['val_loss'][-1] < result_dict['best_val_loss']:
print("{} Epoch, Best epoch was updated! Valid Loss: {: >4.5f}".format(epoch, result_dict['val_loss'][-1]))
result_dict["best_val_loss"] = result_dict['val_loss'][-1]
os.makedirs(output_dir, exist_ok=True)
torch.save(model.state_dict(), f"{output_dir}/pytorch_model.bin")
model_config.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
print(f"Saving model checkpoint to {output_dir}.")
print()
if args.swa:
update_bn(train_dataloader, swa_model, device=torch.device('cuda'))
result_dict = evaluator.swa_evaluate(valid_dataloader, epoch, result_dict)
evaluator.save(result_dict, output_dir)
torch.save(swa_model.state_dict(), f"{output_dir}/swa_pytorch_model.bin")
print()
print(f"Total Training Time: {np.sum(train_time_list)}secs, Average Training Time per Epoch: {np.mean(train_time_list)}secs.")
print(f"Total Validation Time: {np.sum(valid_time_list)}secs, Average Validation Time per Epoch: {np.mean(valid_time_list)}secs.")
torch.cuda.empty_cache()
del trainer, evaluator
del model, model_config, tokenizer
del optimizer, scheduler
del train_dataloader, valid_dataloader, result_dict
del swa_model, swa_scheduler
gc.collect()
for fold in range(5):
print();print()
print('-'*50)
print(f'FOLD: {fold}')
print('-'*50)
run(train, fold)
--------------------------------------------------
FOLD: 0
--------------------------------------------------
Downloading: 0%| | 0.00/481 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/899k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/456k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/1.36M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/501M [00:00<?, ?B/s]
--------------------------------------------------
FOLD: 4
--------------------------------------------------
Model pushed to 1 GPU(s), type Tesla T4.
Num examples Train= 2268, Num examples Valid=566
Total Training Steps: 5670, Total Warmup Steps: 170
Total Training Steps: 5670, Total Warmup Steps: 170, SWA Start Step: 7
Epoch: 00 [ 4/2268 ( 0%)], Train Loss: 1.28283
Epoch: 00 [ 44/2268 ( 2%)], Train Loss: 1.46458
Epoch: 00 [ 84/2268 ( 4%)], Train Loss: 1.35902
Epoch: 00 [ 124/2268 ( 5%)], Train Loss: 1.27820
Epoch: 00 [ 164/2268 ( 7%)], Train Loss: 1.20796
Epoch: 00 [ 204/2268 ( 9%)], Train Loss: 1.17569
Epoch: 00 [ 244/2268 ( 11%)], Train Loss: 1.16979
Epoch: 00 [ 284/2268 ( 13%)], Train Loss: 1.14059
Epoch: 00 [ 324/2268 ( 14%)], Train Loss: 1.10813
Epoch: 00 [ 364/2268 ( 16%)], Train Loss: 1.07296
Epoch: 00 [ 404/2268 ( 18%)], Train Loss: 1.05631
Epoch: 00 [ 444/2268 ( 20%)], Train Loss: 1.04016
Epoch: 00 [ 484/2268 ( 21%)], Train Loss: 1.04325
Epoch: 00 [ 524/2268 ( 23%)], Train Loss: 1.02989
Epoch: 00 [ 564/2268 ( 25%)], Train Loss: 1.02182
Epoch: 00 [ 604/2268 ( 27%)], Train Loss: 1.00966
Epoch: 00 [ 644/2268 ( 28%)], Train Loss: 0.99788
Epoch: 00 [ 684/2268 ( 30%)], Train Loss: 0.97926
Epoch: 00 [ 724/2268 ( 32%)], Train Loss: 0.96476
Epoch: 00 [ 764/2268 ( 34%)], Train Loss: 0.96321
Epoch: 00 [ 804/2268 ( 35%)], Train Loss: 0.96076
Epoch: 00 [ 844/2268 ( 37%)], Train Loss: 0.96500
Epoch: 00 [ 884/2268 ( 39%)], Train Loss: 0.95368
Epoch: 00 [ 924/2268 ( 41%)], Train Loss: 0.94267
Epoch: 00 [ 964/2268 ( 43%)], Train Loss: 0.93685
Epoch: 00 [1004/2268 ( 44%)], Train Loss: 0.92409
Epoch: 00 [1044/2268 ( 46%)], Train Loss: 0.92297
Epoch: 00 [1084/2268 ( 48%)], Train Loss: 0.93101
Epoch: 00 [1124/2268 ( 50%)], Train Loss: 0.93980
Epoch: 00 [1164/2268 ( 51%)], Train Loss: 0.94403
Epoch: 00 [1204/2268 ( 53%)], Train Loss: 0.94146
Epoch: 00 [1244/2268 ( 55%)], Train Loss: 0.93697
Epoch: 00 [1284/2268 ( 57%)], Train Loss: 0.93230
Epoch: 00 [1324/2268 ( 58%)], Train Loss: 0.92753
Epoch: 00 [1364/2268 ( 60%)], Train Loss: 0.92632
Epoch: 00 [1404/2268 ( 62%)], Train Loss: 0.92103
Epoch: 00 [1444/2268 ( 64%)], Train Loss: 0.92005
Epoch: 00 [1484/2268 ( 65%)], Train Loss: 0.91947
Epoch: 00 [1524/2268 ( 67%)], Train Loss: 0.92621
Epoch: 00 [1564/2268 ( 69%)], Train Loss: 0.92526
Epoch: 00 [1604/2268 ( 71%)], Train Loss: 0.92409
Epoch: 00 [1644/2268 ( 72%)], Train Loss: 0.91968
Epoch: 00 [1684/2268 ( 74%)], Train Loss: 0.91536
Epoch: 00 [1724/2268 ( 76%)], Train Loss: 0.91541
Epoch: 00 [1764/2268 ( 78%)], Train Loss: 0.91314
Epoch: 00 [1804/2268 ( 80%)], Train Loss: 0.90783
Epoch: 00 [1844/2268 ( 81%)], Train Loss: 0.90143
Epoch: 00 [1884/2268 ( 83%)], Train Loss: 0.89767
Epoch: 00 [1924/2268 ( 85%)], Train Loss: 0.89671
Epoch: 00 [1964/2268 ( 87%)], Train Loss: 0.90100
Epoch: 00 [2004/2268 ( 88%)], Train Loss: 0.89856
Epoch: 00 [2044/2268 ( 90%)], Train Loss: 0.89740
Epoch: 00 [2084/2268 ( 92%)], Train Loss: 0.89660
Epoch: 00 [2124/2268 ( 94%)], Train Loss: 0.89323
Epoch: 00 [2164/2268 ( 95%)], Train Loss: 0.89318
Epoch: 00 [2204/2268 ( 97%)], Train Loss: 0.89141
Epoch: 00 [2244/2268 ( 99%)], Train Loss: 0.89004
Epoch: 00 [2268/2268 (100%)], Train Loss: 0.89078
----Validation Results Summary----
Epoch: [0] Valid Loss: 0.64503
0 Epoch, Best epoch was updated! Valid Loss: 0.64503
Saving model checkpoint to output/checkpoint-fold-4.
Epoch: 01 [ 4/2268 ( 0%)], Train Loss: 0.53696
Epoch: 01 [ 44/2268 ( 2%)], Train Loss: 0.93457
Epoch: 01 [ 84/2268 ( 4%)], Train Loss: 0.87621
Epoch: 01 [ 124/2268 ( 5%)], Train Loss: 0.81533
Epoch: 01 [ 164/2268 ( 7%)], Train Loss: 0.77257
Epoch: 01 [ 204/2268 ( 9%)], Train Loss: 0.79076
Epoch: 01 [ 244/2268 ( 11%)], Train Loss: 0.78069
Epoch: 01 [ 284/2268 ( 13%)], Train Loss: 0.77692
Epoch: 01 [ 324/2268 ( 14%)], Train Loss: 0.75880
Epoch: 01 [ 364/2268 ( 16%)], Train Loss: 0.74663
Epoch: 01 [ 404/2268 ( 18%)], Train Loss: 0.76209
Epoch: 01 [ 444/2268 ( 20%)], Train Loss: 0.77083
Epoch: 01 [ 484/2268 ( 21%)], Train Loss: 0.76548
Epoch: 01 [ 524/2268 ( 23%)], Train Loss: 0.76515
Epoch: 01 [ 564/2268 ( 25%)], Train Loss: 0.75849
Epoch: 01 [ 604/2268 ( 27%)], Train Loss: 0.74597
Epoch: 01 [ 644/2268 ( 28%)], Train Loss: 0.74057
Epoch: 01 [ 684/2268 ( 30%)], Train Loss: 0.73218
Epoch: 01 [ 724/2268 ( 32%)], Train Loss: 0.72604
Epoch: 01 [ 764/2268 ( 34%)], Train Loss: 0.73348
Epoch: 01 [ 804/2268 ( 35%)], Train Loss: 0.73147
Epoch: 01 [ 844/2268 ( 37%)], Train Loss: 0.72382
Epoch: 01 [ 884/2268 ( 39%)], Train Loss: 0.71607
Epoch: 01 [ 924/2268 ( 41%)], Train Loss: 0.70824
Epoch: 01 [ 964/2268 ( 43%)], Train Loss: 0.70795
Epoch: 01 [1004/2268 ( 44%)], Train Loss: 0.70372
Epoch: 01 [1044/2268 ( 46%)], Train Loss: 0.70557
Epoch: 01 [1084/2268 ( 48%)], Train Loss: 0.70596
Epoch: 01 [1124/2268 ( 50%)], Train Loss: 0.70677
Epoch: 01 [1164/2268 ( 51%)], Train Loss: 0.70345
Epoch: 01 [1204/2268 ( 53%)], Train Loss: 0.69868
Epoch: 01 [1244/2268 ( 55%)], Train Loss: 0.70097
Epoch: 01 [1284/2268 ( 57%)], Train Loss: 0.69837
Epoch: 01 [1324/2268 ( 58%)], Train Loss: 0.69784
Epoch: 01 [1364/2268 ( 60%)], Train Loss: 0.69726
Epoch: 01 [1404/2268 ( 62%)], Train Loss: 0.69253
Epoch: 01 [1444/2268 ( 64%)], Train Loss: 0.69333
Epoch: 01 [1484/2268 ( 65%)], Train Loss: 0.69478
Epoch: 01 [1524/2268 ( 67%)], Train Loss: 0.69764
Epoch: 01 [1564/2268 ( 69%)], Train Loss: 0.69436
Epoch: 01 [1604/2268 ( 71%)], Train Loss: 0.69109
Epoch: 01 [1644/2268 ( 72%)], Train Loss: 0.68601
Epoch: 01 [1684/2268 ( 74%)], Train Loss: 0.68686
Epoch: 01 [1724/2268 ( 76%)], Train Loss: 0.68302
Epoch: 01 [1764/2268 ( 78%)], Train Loss: 0.68247
Epoch: 01 [1804/2268 ( 80%)], Train Loss: 0.68027
Epoch: 01 [1844/2268 ( 81%)], Train Loss: 0.67921
Epoch: 01 [1884/2268 ( 83%)], Train Loss: 0.67613
Epoch: 01 [1924/2268 ( 85%)], Train Loss: 0.67496
Epoch: 01 [1964/2268 ( 87%)], Train Loss: 0.67878
Epoch: 01 [2004/2268 ( 88%)], Train Loss: 0.67810
Epoch: 01 [2044/2268 ( 90%)], Train Loss: 0.67787
Epoch: 01 [2084/2268 ( 92%)], Train Loss: 0.67812
Epoch: 01 [2124/2268 ( 94%)], Train Loss: 0.67632
Epoch: 01 [2164/2268 ( 95%)], Train Loss: 0.67559
Epoch: 01 [2204/2268 ( 97%)], Train Loss: 0.67443
Epoch: 01 [2244/2268 ( 99%)], Train Loss: 0.67658
Epoch: 01 [2268/2268 (100%)], Train Loss: 0.67583
----Validation Results Summary----
Epoch: [1] Valid Loss: 0.55653
1 Epoch, Best epoch was updated! Valid Loss: 0.55653
Saving model checkpoint to output/checkpoint-fold-4.
Epoch: 02 [ 4/2268 ( 0%)], Train Loss: 0.45402
Epoch: 02 [ 44/2268 ( 2%)], Train Loss: 0.64306
Epoch: 02 [ 84/2268 ( 4%)], Train Loss: 0.62823
Epoch: 02 [ 124/2268 ( 5%)], Train Loss: 0.58466
Epoch: 02 [ 164/2268 ( 7%)], Train Loss: 0.60167
Epoch: 02 [ 204/2268 ( 9%)], Train Loss: 0.62674
Epoch: 02 [ 244/2268 ( 11%)], Train Loss: 0.62825
Epoch: 02 [ 284/2268 ( 13%)], Train Loss: 0.61454
Epoch: 02 [ 324/2268 ( 14%)], Train Loss: 0.60417
Epoch: 02 [ 364/2268 ( 16%)], Train Loss: 0.59780
Epoch: 02 [ 404/2268 ( 18%)], Train Loss: 0.59660
Epoch: 02 [ 444/2268 ( 20%)], Train Loss: 0.58675
Epoch: 02 [ 484/2268 ( 21%)], Train Loss: 0.57407
Epoch: 02 [ 524/2268 ( 23%)], Train Loss: 0.57115
Epoch: 02 [ 564/2268 ( 25%)], Train Loss: 0.57042
Epoch: 02 [ 604/2268 ( 27%)], Train Loss: 0.56882
Epoch: 02 [ 644/2268 ( 28%)], Train Loss: 0.56610
Epoch: 02 [ 684/2268 ( 30%)], Train Loss: 0.55726
Epoch: 02 [ 724/2268 ( 32%)], Train Loss: 0.55191
Epoch: 02 [ 764/2268 ( 34%)], Train Loss: 0.55895
Epoch: 02 [ 804/2268 ( 35%)], Train Loss: 0.56977
Epoch: 02 [ 844/2268 ( 37%)], Train Loss: 0.57463
Epoch: 02 [ 884/2268 ( 39%)], Train Loss: 0.57718
Epoch: 02 [ 924/2268 ( 41%)], Train Loss: 0.57418
Epoch: 02 [ 964/2268 ( 43%)], Train Loss: 0.57769
Epoch: 02 [1004/2268 ( 44%)], Train Loss: 0.57488
Epoch: 02 [1044/2268 ( 46%)], Train Loss: 0.57814
Epoch: 02 [1084/2268 ( 48%)], Train Loss: 0.58521
Epoch: 02 [1124/2268 ( 50%)], Train Loss: 0.58364
Epoch: 02 [1164/2268 ( 51%)], Train Loss: 0.57711
Epoch: 02 [1204/2268 ( 53%)], Train Loss: 0.57456
Epoch: 02 [1244/2268 ( 55%)], Train Loss: 0.57723
Epoch: 02 [1284/2268 ( 57%)], Train Loss: 0.57799
Epoch: 02 [1324/2268 ( 58%)], Train Loss: 0.57730
Epoch: 02 [1364/2268 ( 60%)], Train Loss: 0.58816
Epoch: 02 [1404/2268 ( 62%)], Train Loss: 0.59114
Epoch: 02 [1444/2268 ( 64%)], Train Loss: 0.59238
Epoch: 02 [1484/2268 ( 65%)], Train Loss: 0.59219
Epoch: 02 [1524/2268 ( 67%)], Train Loss: 0.58864
Epoch: 02 [1564/2268 ( 69%)], Train Loss: 0.58567
Epoch: 02 [1604/2268 ( 71%)], Train Loss: 0.58255
Epoch: 02 [1644/2268 ( 72%)], Train Loss: 0.57710
Epoch: 02 [1684/2268 ( 74%)], Train Loss: 0.57643
Epoch: 02 [1724/2268 ( 76%)], Train Loss: 0.57495
Epoch: 02 [1764/2268 ( 78%)], Train Loss: 0.57549
Epoch: 02 [1804/2268 ( 80%)], Train Loss: 0.57183
Epoch: 02 [1844/2268 ( 81%)], Train Loss: 0.56976
Epoch: 02 [1884/2268 ( 83%)], Train Loss: 0.56983
Epoch: 02 [1924/2268 ( 85%)], Train Loss: 0.56750
Epoch: 02 [1964/2268 ( 87%)], Train Loss: 0.56978
Epoch: 02 [2004/2268 ( 88%)], Train Loss: 0.57045
Epoch: 02 [2044/2268 ( 90%)], Train Loss: 0.57403
Epoch: 02 [2084/2268 ( 92%)], Train Loss: 0.57786
Epoch: 02 [2124/2268 ( 94%)], Train Loss: 0.57913
Epoch: 02 [2164/2268 ( 95%)], Train Loss: 0.58155
Epoch: 02 [2204/2268 ( 97%)], Train Loss: 0.58228
Epoch: 02 [2244/2268 ( 99%)], Train Loss: 0.58125
Epoch: 02 [2268/2268 (100%)], Train Loss: 0.57991
----Validation Results Summary----
Epoch: [2] Valid Loss: 0.66430
Epoch: 03 [ 4/2268 ( 0%)], Train Loss: 0.62644
Epoch: 03 [ 44/2268 ( 2%)], Train Loss: 0.61489
Epoch: 03 [ 84/2268 ( 4%)], Train Loss: 0.59724
Epoch: 03 [ 124/2268 ( 5%)], Train Loss: 0.52507
Epoch: 03 [ 164/2268 ( 7%)], Train Loss: 0.49866
Epoch: 03 [ 204/2268 ( 9%)], Train Loss: 0.51217
Epoch: 03 [ 244/2268 ( 11%)], Train Loss: 0.49419
Epoch: 03 [ 284/2268 ( 13%)], Train Loss: 0.49282
Epoch: 03 [ 324/2268 ( 14%)], Train Loss: 0.49159
Epoch: 03 [ 364/2268 ( 16%)], Train Loss: 0.48985
Epoch: 03 [ 404/2268 ( 18%)], Train Loss: 0.50270
Epoch: 03 [ 444/2268 ( 20%)], Train Loss: 0.49203
Epoch: 03 [ 484/2268 ( 21%)], Train Loss: 0.48105
Epoch: 03 [ 524/2268 ( 23%)], Train Loss: 0.47946
Epoch: 03 [ 564/2268 ( 25%)], Train Loss: 0.48215
Epoch: 03 [ 604/2268 ( 27%)], Train Loss: 0.49273
Epoch: 03 [ 644/2268 ( 28%)], Train Loss: 0.49164
Epoch: 03 [ 684/2268 ( 30%)], Train Loss: 0.49678
Epoch: 03 [ 724/2268 ( 32%)], Train Loss: 0.48978
Epoch: 03 [ 764/2268 ( 34%)], Train Loss: 0.49203
Epoch: 03 [ 804/2268 ( 35%)], Train Loss: 0.49114
Epoch: 03 [ 844/2268 ( 37%)], Train Loss: 0.49380
Epoch: 03 [ 884/2268 ( 39%)], Train Loss: 0.48945
Epoch: 03 [ 924/2268 ( 41%)], Train Loss: 0.48984
Epoch: 03 [ 964/2268 ( 43%)], Train Loss: 0.49087
Epoch: 03 [1004/2268 ( 44%)], Train Loss: 0.48917
Epoch: 03 [1044/2268 ( 46%)], Train Loss: 0.48928
Epoch: 03 [1084/2268 ( 48%)], Train Loss: 0.48859
Epoch: 03 [1124/2268 ( 50%)], Train Loss: 0.49008
Epoch: 03 [1164/2268 ( 51%)], Train Loss: 0.49300
Epoch: 03 [1204/2268 ( 53%)], Train Loss: 0.49025
Epoch: 03 [1244/2268 ( 55%)], Train Loss: 0.49027
Epoch: 03 [1284/2268 ( 57%)], Train Loss: 0.49444
Epoch: 03 [1324/2268 ( 58%)], Train Loss: 0.49684
Epoch: 03 [1364/2268 ( 60%)], Train Loss: 0.50332
Epoch: 03 [1404/2268 ( 62%)], Train Loss: 0.50896
Epoch: 03 [1444/2268 ( 64%)], Train Loss: 0.50900
Epoch: 03 [1484/2268 ( 65%)], Train Loss: 0.50870
Epoch: 03 [1524/2268 ( 67%)], Train Loss: 0.50740
Epoch: 03 [1564/2268 ( 69%)], Train Loss: 0.50650
Epoch: 03 [1604/2268 ( 71%)], Train Loss: 0.50101
Epoch: 03 [1644/2268 ( 72%)], Train Loss: 0.49765
Epoch: 03 [1684/2268 ( 74%)], Train Loss: 0.49345
Epoch: 03 [1724/2268 ( 76%)], Train Loss: 0.48961
Epoch: 03 [1764/2268 ( 78%)], Train Loss: 0.48817
Epoch: 03 [1804/2268 ( 80%)], Train Loss: 0.48583
Epoch: 03 [1844/2268 ( 81%)], Train Loss: 0.48523
Epoch: 03 [1884/2268 ( 83%)], Train Loss: 0.48385
Epoch: 03 [1924/2268 ( 85%)], Train Loss: 0.48323
Epoch: 03 [1964/2268 ( 87%)], Train Loss: 0.48650
Epoch: 03 [2004/2268 ( 88%)], Train Loss: 0.48749
Epoch: 03 [2044/2268 ( 90%)], Train Loss: 0.48876
Epoch: 03 [2084/2268 ( 92%)], Train Loss: 0.49047
Epoch: 03 [2124/2268 ( 94%)], Train Loss: 0.49103
Epoch: 03 [2164/2268 ( 95%)], Train Loss: 0.49322
Epoch: 03 [2204/2268 ( 97%)], Train Loss: 0.49296
Epoch: 03 [2244/2268 ( 99%)], Train Loss: 0.49401
Epoch: 03 [2268/2268 (100%)], Train Loss: 0.49397
----Validation Results Summary----
Epoch: [3] Valid Loss: 0.58907
Epoch: 04 [ 4/2268 ( 0%)], Train Loss: 0.64992
Epoch: 04 [ 44/2268 ( 2%)], Train Loss: 0.65384
Epoch: 04 [ 84/2268 ( 4%)], Train Loss: 0.64771
Epoch: 04 [ 124/2268 ( 5%)], Train Loss: 0.61029
Epoch: 04 [ 164/2268 ( 7%)], Train Loss: 0.57436
Epoch: 04 [ 204/2268 ( 9%)], Train Loss: 0.55770
Epoch: 04 [ 244/2268 ( 11%)], Train Loss: 0.53102
Epoch: 04 [ 284/2268 ( 13%)], Train Loss: 0.50547
Epoch: 04 [ 324/2268 ( 14%)], Train Loss: 0.50709
Epoch: 04 [ 364/2268 ( 16%)], Train Loss: 0.49273
Epoch: 04 [ 404/2268 ( 18%)], Train Loss: 0.49406
Epoch: 04 [ 444/2268 ( 20%)], Train Loss: 0.49022
Epoch: 04 [ 484/2268 ( 21%)], Train Loss: 0.49322
Epoch: 04 [ 524/2268 ( 23%)], Train Loss: 0.48910
Epoch: 04 [ 564/2268 ( 25%)], Train Loss: 0.48542
Epoch: 04 [ 604/2268 ( 27%)], Train Loss: 0.48497
Epoch: 04 [ 644/2268 ( 28%)], Train Loss: 0.49642
Epoch: 04 [ 684/2268 ( 30%)], Train Loss: 0.50969
Epoch: 04 [ 724/2268 ( 32%)], Train Loss: 0.50384
Epoch: 04 [ 764/2268 ( 34%)], Train Loss: 0.50962
Epoch: 04 [ 804/2268 ( 35%)], Train Loss: 0.51035
Epoch: 04 [ 844/2268 ( 37%)], Train Loss: 0.50589
Epoch: 04 [ 884/2268 ( 39%)], Train Loss: 0.50207
Epoch: 04 [ 924/2268 ( 41%)], Train Loss: 0.49947
Epoch: 04 [ 964/2268 ( 43%)], Train Loss: 0.50121
Epoch: 04 [1004/2268 ( 44%)], Train Loss: 0.50006
Epoch: 04 [1044/2268 ( 46%)], Train Loss: 0.49646
Epoch: 04 [1084/2268 ( 48%)], Train Loss: 0.49469
Epoch: 04 [1124/2268 ( 50%)], Train Loss: 0.48781
Epoch: 04 [1164/2268 ( 51%)], Train Loss: 0.48834
Epoch: 04 [1204/2268 ( 53%)], Train Loss: 0.48828
Epoch: 04 [1244/2268 ( 55%)], Train Loss: 0.49121
Epoch: 04 [1284/2268 ( 57%)], Train Loss: 0.49205
Epoch: 04 [1324/2268 ( 58%)], Train Loss: 0.48969
Epoch: 04 [1364/2268 ( 60%)], Train Loss: 0.48980
Epoch: 04 [1404/2268 ( 62%)], Train Loss: 0.49524
Epoch: 04 [1444/2268 ( 64%)], Train Loss: 0.49559
Epoch: 04 [1484/2268 ( 65%)], Train Loss: 0.49774
Epoch: 04 [1524/2268 ( 67%)], Train Loss: 0.50104
Epoch: 04 [1564/2268 ( 69%)], Train Loss: 0.50761
Epoch: 04 [1604/2268 ( 71%)], Train Loss: 0.50510
Epoch: 04 [1644/2268 ( 72%)], Train Loss: 0.50070
Epoch: 04 [1684/2268 ( 74%)], Train Loss: 0.49743
Epoch: 04 [1724/2268 ( 76%)], Train Loss: 0.49462
Epoch: 04 [1764/2268 ( 78%)], Train Loss: 0.49392
Epoch: 04 [1804/2268 ( 80%)], Train Loss: 0.49185
Epoch: 04 [1844/2268 ( 81%)], Train Loss: 0.49117
Epoch: 04 [1884/2268 ( 83%)], Train Loss: 0.49019
Epoch: 04 [1924/2268 ( 85%)], Train Loss: 0.49012
Epoch: 04 [1964/2268 ( 87%)], Train Loss: 0.49117
Epoch: 04 [2004/2268 ( 88%)], Train Loss: 0.49079
Epoch: 04 [2044/2268 ( 90%)], Train Loss: 0.48898
Epoch: 04 [2084/2268 ( 92%)], Train Loss: 0.49089
Epoch: 04 [2124/2268 ( 94%)], Train Loss: 0.49206
Epoch: 04 [2164/2268 ( 95%)], Train Loss: 0.49211
Epoch: 04 [2204/2268 ( 97%)], Train Loss: 0.49082
Epoch: 04 [2244/2268 ( 99%)], Train Loss: 0.49424
Epoch: 04 [2268/2268 (100%)], Train Loss: 0.49522
----Validation Results Summary----
Epoch: [4] Valid Loss: 0.71013
Epoch: 05 [ 4/2268 ( 0%)], Train Loss: 0.44311
Epoch: 05 [ 44/2268 ( 2%)], Train Loss: 0.41894
Epoch: 05 [ 84/2268 ( 4%)], Train Loss: 0.38474
Epoch: 05 [ 124/2268 ( 5%)], Train Loss: 0.38484
Epoch: 05 [ 164/2268 ( 7%)], Train Loss: 0.38770
Epoch: 05 [ 204/2268 ( 9%)], Train Loss: 0.37430
Epoch: 05 [ 244/2268 ( 11%)], Train Loss: 0.36209
Epoch: 05 [ 284/2268 ( 13%)], Train Loss: 0.37460
Epoch: 05 [ 324/2268 ( 14%)], Train Loss: 0.40471
Epoch: 05 [ 364/2268 ( 16%)], Train Loss: 0.41147
Epoch: 05 [ 404/2268 ( 18%)], Train Loss: 0.40943
Epoch: 05 [ 444/2268 ( 20%)], Train Loss: 0.40370
Epoch: 05 [ 484/2268 ( 21%)], Train Loss: 0.39646
Epoch: 05 [ 524/2268 ( 23%)], Train Loss: 0.39260
Epoch: 05 [ 564/2268 ( 25%)], Train Loss: 0.38579
Epoch: 05 [ 604/2268 ( 27%)], Train Loss: 0.38290
Epoch: 05 [ 644/2268 ( 28%)], Train Loss: 0.39178
Epoch: 05 [ 684/2268 ( 30%)], Train Loss: 0.40288
Epoch: 05 [ 724/2268 ( 32%)], Train Loss: 0.40203
Epoch: 05 [ 764/2268 ( 34%)], Train Loss: 0.40541
Epoch: 05 [ 804/2268 ( 35%)], Train Loss: 0.40350
Epoch: 05 [ 844/2268 ( 37%)], Train Loss: 0.40158
Epoch: 05 [ 884/2268 ( 39%)], Train Loss: 0.40417
Epoch: 05 [ 924/2268 ( 41%)], Train Loss: 0.39938
Epoch: 05 [ 964/2268 ( 43%)], Train Loss: 0.39874
Epoch: 05 [1004/2268 ( 44%)], Train Loss: 0.40238
Epoch: 05 [1044/2268 ( 46%)], Train Loss: 0.40243
Epoch: 05 [1084/2268 ( 48%)], Train Loss: 0.40301
Epoch: 05 [1124/2268 ( 50%)], Train Loss: 0.40019
Epoch: 05 [1164/2268 ( 51%)], Train Loss: 0.40425
Epoch: 05 [1204/2268 ( 53%)], Train Loss: 0.40677
Epoch: 05 [1244/2268 ( 55%)], Train Loss: 0.40896
Epoch: 05 [1284/2268 ( 57%)], Train Loss: 0.40850
Epoch: 05 [1324/2268 ( 58%)], Train Loss: 0.40529
Epoch: 05 [1364/2268 ( 60%)], Train Loss: 0.40391
Epoch: 05 [1404/2268 ( 62%)], Train Loss: 0.40296
Epoch: 05 [1444/2268 ( 64%)], Train Loss: 0.40108
Epoch: 05 [1484/2268 ( 65%)], Train Loss: 0.40191
Epoch: 05 [1524/2268 ( 67%)], Train Loss: 0.40492
Epoch: 05 [1564/2268 ( 69%)], Train Loss: 0.40781
Epoch: 05 [1604/2268 ( 71%)], Train Loss: 0.40716
Epoch: 05 [1644/2268 ( 72%)], Train Loss: 0.40614
Epoch: 05 [1684/2268 ( 74%)], Train Loss: 0.40752
Epoch: 05 [1724/2268 ( 76%)], Train Loss: 0.40781
Epoch: 05 [1764/2268 ( 78%)], Train Loss: 0.41299
Epoch: 05 [1804/2268 ( 80%)], Train Loss: 0.41056
Epoch: 05 [1844/2268 ( 81%)], Train Loss: 0.40837
Epoch: 05 [1884/2268 ( 83%)], Train Loss: 0.40473
Epoch: 05 [1924/2268 ( 85%)], Train Loss: 0.40497
Epoch: 05 [1964/2268 ( 87%)], Train Loss: 0.40560
Epoch: 05 [2004/2268 ( 88%)], Train Loss: 0.40797
Epoch: 05 [2044/2268 ( 90%)], Train Loss: 0.40658
Epoch: 05 [2084/2268 ( 92%)], Train Loss: 0.40506
Epoch: 05 [2124/2268 ( 94%)], Train Loss: 0.40283
Epoch: 05 [2164/2268 ( 95%)], Train Loss: 0.40100
Epoch: 05 [2204/2268 ( 97%)], Train Loss: 0.39943
Epoch: 05 [2244/2268 ( 99%)], Train Loss: 0.39852
Epoch: 05 [2268/2268 (100%)], Train Loss: 0.39651
----Validation Results Summary----
Epoch: [5] Valid Loss: 0.57167
Epoch: 06 [ 4/2268 ( 0%)], Train Loss: 0.07560
Epoch: 06 [ 44/2268 ( 2%)], Train Loss: 0.25473
Epoch: 06 [ 84/2268 ( 4%)], Train Loss: 0.23337
Epoch: 06 [ 124/2268 ( 5%)], Train Loss: 0.25824
Epoch: 06 [ 164/2268 ( 7%)], Train Loss: 0.27940
Epoch: 06 [ 204/2268 ( 9%)], Train Loss: 0.29314
Epoch: 06 [ 244/2268 ( 11%)], Train Loss: 0.29825
Epoch: 06 [ 284/2268 ( 13%)], Train Loss: 0.28348
Epoch: 06 [ 324/2268 ( 14%)], Train Loss: 0.28890
Epoch: 06 [ 364/2268 ( 16%)], Train Loss: 0.28588
Epoch: 06 [ 404/2268 ( 18%)], Train Loss: 0.29583
Epoch: 06 [ 444/2268 ( 20%)], Train Loss: 0.28808
Epoch: 06 [ 484/2268 ( 21%)], Train Loss: 0.29125
Epoch: 06 [ 524/2268 ( 23%)], Train Loss: 0.29303
Epoch: 06 [ 564/2268 ( 25%)], Train Loss: 0.29549
Epoch: 06 [ 604/2268 ( 27%)], Train Loss: 0.30263
Epoch: 06 [ 644/2268 ( 28%)], Train Loss: 0.30517
Epoch: 06 [ 684/2268 ( 30%)], Train Loss: 0.31541
Epoch: 06 [ 724/2268 ( 32%)], Train Loss: 0.31276
Epoch: 06 [ 764/2268 ( 34%)], Train Loss: 0.31512
Epoch: 06 [ 804/2268 ( 35%)], Train Loss: 0.31307
Epoch: 06 [ 844/2268 ( 37%)], Train Loss: 0.31571
Epoch: 06 [ 884/2268 ( 39%)], Train Loss: 0.31498
Epoch: 06 [ 924/2268 ( 41%)], Train Loss: 0.32180
Epoch: 06 [ 964/2268 ( 43%)], Train Loss: 0.32639
Epoch: 06 [1004/2268 ( 44%)], Train Loss: 0.32887
Epoch: 06 [1044/2268 ( 46%)], Train Loss: 0.33220
Epoch: 06 [1084/2268 ( 48%)], Train Loss: 0.33477
Epoch: 06 [1124/2268 ( 50%)], Train Loss: 0.34232
Epoch: 06 [1164/2268 ( 51%)], Train Loss: 0.34216
Epoch: 06 [1204/2268 ( 53%)], Train Loss: 0.33795
Epoch: 06 [1244/2268 ( 55%)], Train Loss: 0.33476
Epoch: 06 [1284/2268 ( 57%)], Train Loss: 0.33147
Epoch: 06 [1324/2268 ( 58%)], Train Loss: 0.32758
Epoch: 06 [1364/2268 ( 60%)], Train Loss: 0.32606
Epoch: 06 [1404/2268 ( 62%)], Train Loss: 0.32382
Epoch: 06 [1444/2268 ( 64%)], Train Loss: 0.32190
Epoch: 06 [1484/2268 ( 65%)], Train Loss: 0.32272
Epoch: 06 [1524/2268 ( 67%)], Train Loss: 0.32692
Epoch: 06 [1564/2268 ( 69%)], Train Loss: 0.32793
Epoch: 06 [1604/2268 ( 71%)], Train Loss: 0.32638
Epoch: 06 [1644/2268 ( 72%)], Train Loss: 0.32809
Epoch: 06 [1684/2268 ( 74%)], Train Loss: 0.32676
Epoch: 06 [1724/2268 ( 76%)], Train Loss: 0.32427
Epoch: 06 [1764/2268 ( 78%)], Train Loss: 0.32590
Epoch: 06 [1804/2268 ( 80%)], Train Loss: 0.32504
Epoch: 06 [1844/2268 ( 81%)], Train Loss: 0.32545
Epoch: 06 [1884/2268 ( 83%)], Train Loss: 0.32462
Epoch: 06 [1924/2268 ( 85%)], Train Loss: 0.32334
Epoch: 06 [1964/2268 ( 87%)], Train Loss: 0.32397
Epoch: 06 [2004/2268 ( 88%)], Train Loss: 0.32404
Epoch: 06 [2044/2268 ( 90%)], Train Loss: 0.32197
Epoch: 06 [2084/2268 ( 92%)], Train Loss: 0.32043
Epoch: 06 [2124/2268 ( 94%)], Train Loss: 0.31887
Epoch: 06 [2164/2268 ( 95%)], Train Loss: 0.31712
Epoch: 06 [2204/2268 ( 97%)], Train Loss: 0.31581
Epoch: 06 [2244/2268 ( 99%)], Train Loss: 0.31366
Epoch: 06 [2268/2268 (100%)], Train Loss: 0.31351
----Validation Results Summary----
Epoch: [6] Valid Loss: 0.62137
Epoch: 07 [ 4/2268 ( 0%)], Train Loss: 0.26883
Epoch: 07 [ 44/2268 ( 2%)], Train Loss: 0.39348
Epoch: 07 [ 84/2268 ( 4%)], Train Loss: 0.31924
Epoch: 07 [ 124/2268 ( 5%)], Train Loss: 0.32539
Epoch: 07 [ 164/2268 ( 7%)], Train Loss: 0.32082
Epoch: 07 [ 204/2268 ( 9%)], Train Loss: 0.32421
Epoch: 07 [ 244/2268 ( 11%)], Train Loss: 0.36910
Epoch: 07 [ 284/2268 ( 13%)], Train Loss: 0.38997
Epoch: 07 [ 324/2268 ( 14%)], Train Loss: 0.40966
Epoch: 07 [ 364/2268 ( 16%)], Train Loss: 0.41173
Epoch: 07 [ 404/2268 ( 18%)], Train Loss: 0.41226
Epoch: 07 [ 444/2268 ( 20%)], Train Loss: 0.42064
Epoch: 07 [ 484/2268 ( 21%)], Train Loss: 0.42729
Epoch: 07 [ 524/2268 ( 23%)], Train Loss: 0.43285
Epoch: 07 [ 564/2268 ( 25%)], Train Loss: 0.43128
Epoch: 07 [ 604/2268 ( 27%)], Train Loss: 0.42472
Epoch: 07 [ 644/2268 ( 28%)], Train Loss: 0.42846
Epoch: 07 [ 684/2268 ( 30%)], Train Loss: 0.43004
Epoch: 07 [ 724/2268 ( 32%)], Train Loss: 0.42993
Epoch: 07 [ 764/2268 ( 34%)], Train Loss: 0.43494
Epoch: 07 [ 804/2268 ( 35%)], Train Loss: 0.43462
Epoch: 07 [ 844/2268 ( 37%)], Train Loss: 0.43741
Epoch: 07 [ 884/2268 ( 39%)], Train Loss: 0.43537
Epoch: 07 [ 924/2268 ( 41%)], Train Loss: 0.43573
Epoch: 07 [ 964/2268 ( 43%)], Train Loss: 0.43738
Epoch: 07 [1004/2268 ( 44%)], Train Loss: 0.43760
Epoch: 07 [1044/2268 ( 46%)], Train Loss: 0.43678
Epoch: 07 [1084/2268 ( 48%)], Train Loss: 0.43468
Epoch: 07 [1124/2268 ( 50%)], Train Loss: 0.43622
Epoch: 07 [1164/2268 ( 51%)], Train Loss: 0.43528
Epoch: 07 [1204/2268 ( 53%)], Train Loss: 0.43740
Epoch: 07 [1244/2268 ( 55%)], Train Loss: 0.43622
Epoch: 07 [1284/2268 ( 57%)], Train Loss: 0.43852
Epoch: 07 [1324/2268 ( 58%)], Train Loss: 0.43787
Epoch: 07 [1364/2268 ( 60%)], Train Loss: 0.43789
Epoch: 07 [1404/2268 ( 62%)], Train Loss: 0.43781
Epoch: 07 [1444/2268 ( 64%)], Train Loss: 0.44078
Epoch: 07 [1484/2268 ( 65%)], Train Loss: 0.44062
Epoch: 07 [1524/2268 ( 67%)], Train Loss: 0.43949
Epoch: 07 [1564/2268 ( 69%)], Train Loss: 0.43747
Epoch: 07 [1604/2268 ( 71%)], Train Loss: 0.43456
Epoch: 07 [1644/2268 ( 72%)], Train Loss: 0.43456
Epoch: 07 [1684/2268 ( 74%)], Train Loss: 0.43629
Epoch: 07 [1724/2268 ( 76%)], Train Loss: 0.43475
Epoch: 07 [1764/2268 ( 78%)], Train Loss: 0.43433
Epoch: 07 [1804/2268 ( 80%)], Train Loss: 0.43318
Epoch: 07 [1844/2268 ( 81%)], Train Loss: 0.43294
Epoch: 07 [1884/2268 ( 83%)], Train Loss: 0.43651
Epoch: 07 [1924/2268 ( 85%)], Train Loss: 0.43664
Epoch: 07 [1964/2268 ( 87%)], Train Loss: 0.44019
Epoch: 07 [2004/2268 ( 88%)], Train Loss: 0.44092
Epoch: 07 [2044/2268 ( 90%)], Train Loss: 0.43922
Epoch: 07 [2084/2268 ( 92%)], Train Loss: 0.44204
Epoch: 07 [2124/2268 ( 94%)], Train Loss: 0.44497
Epoch: 07 [2164/2268 ( 95%)], Train Loss: 0.44875
Epoch: 07 [2204/2268 ( 97%)], Train Loss: 0.45062
Epoch: 07 [2244/2268 ( 99%)], Train Loss: 0.45064
Epoch: 07 [2268/2268 (100%)], Train Loss: 0.45216
----Validation Results Summary----
Epoch: [7] Valid Loss: 0.61448
Epoch: 08 [ 4/2268 ( 0%)], Train Loss: 0.55126
Epoch: 08 [ 44/2268 ( 2%)], Train Loss: 0.68165
Epoch: 08 [ 84/2268 ( 4%)], Train Loss: 0.85840
Epoch: 08 [ 124/2268 ( 5%)], Train Loss: 0.82370
Epoch: 08 [ 164/2268 ( 7%)], Train Loss: 0.77338
Epoch: 08 [ 204/2268 ( 9%)], Train Loss: 0.73273
Epoch: 08 [ 244/2268 ( 11%)], Train Loss: 0.71815
Epoch: 08 [ 284/2268 ( 13%)], Train Loss: 0.76542
Epoch: 08 [ 324/2268 ( 14%)], Train Loss: 0.78047
Epoch: 08 [ 364/2268 ( 16%)], Train Loss: 0.80617
Epoch: 08 [ 404/2268 ( 18%)], Train Loss: 0.82592
Epoch: 08 [ 444/2268 ( 20%)], Train Loss: 0.84798
Epoch: 08 [ 484/2268 ( 21%)], Train Loss: 0.86141
Epoch: 08 [ 524/2268 ( 23%)], Train Loss: 0.85377
Epoch: 08 [ 564/2268 ( 25%)], Train Loss: 0.85273
Epoch: 08 [ 604/2268 ( 27%)], Train Loss: 0.83836
Epoch: 08 [ 644/2268 ( 28%)], Train Loss: 0.83272
Epoch: 08 [ 684/2268 ( 30%)], Train Loss: 0.81945
Epoch: 08 [ 724/2268 ( 32%)], Train Loss: 0.80475
Epoch: 08 [ 764/2268 ( 34%)], Train Loss: 0.80558
Epoch: 08 [ 804/2268 ( 35%)], Train Loss: 0.80234
Epoch: 08 [ 844/2268 ( 37%)], Train Loss: 0.80829
Epoch: 08 [ 884/2268 ( 39%)], Train Loss: 0.80554
Epoch: 08 [ 924/2268 ( 41%)], Train Loss: 0.79954
Epoch: 08 [ 964/2268 ( 43%)], Train Loss: 0.79600
Epoch: 08 [1004/2268 ( 44%)], Train Loss: 0.78741
Epoch: 08 [1044/2268 ( 46%)], Train Loss: 0.78327
Epoch: 08 [1084/2268 ( 48%)], Train Loss: 0.77784
Epoch: 08 [1124/2268 ( 50%)], Train Loss: 0.77266
Epoch: 08 [1164/2268 ( 51%)], Train Loss: 0.76717
Epoch: 08 [1204/2268 ( 53%)], Train Loss: 0.76608
Epoch: 08 [1244/2268 ( 55%)], Train Loss: 0.76200
Epoch: 08 [1284/2268 ( 57%)], Train Loss: 0.76095
Epoch: 08 [1324/2268 ( 58%)], Train Loss: 0.76288
Epoch: 08 [1364/2268 ( 60%)], Train Loss: 0.76140
Epoch: 08 [1404/2268 ( 62%)], Train Loss: 0.75777
Epoch: 08 [1444/2268 ( 64%)], Train Loss: 0.75414
Epoch: 08 [1484/2268 ( 65%)], Train Loss: 0.75159
Epoch: 08 [1524/2268 ( 67%)], Train Loss: 0.75506
Epoch: 08 [1564/2268 ( 69%)], Train Loss: 0.74989
Epoch: 08 [1604/2268 ( 71%)], Train Loss: 0.74496
Epoch: 08 [1644/2268 ( 72%)], Train Loss: 0.74204
Epoch: 08 [1684/2268 ( 74%)], Train Loss: 0.73731
Epoch: 08 [1724/2268 ( 76%)], Train Loss: 0.73458
Epoch: 08 [1764/2268 ( 78%)], Train Loss: 0.73397
Epoch: 08 [1804/2268 ( 80%)], Train Loss: 0.73389
Epoch: 08 [1844/2268 ( 81%)], Train Loss: 0.73633
Epoch: 08 [1884/2268 ( 83%)], Train Loss: 0.73581
Epoch: 08 [1924/2268 ( 85%)], Train Loss: 0.73558
Epoch: 08 [1964/2268 ( 87%)], Train Loss: 0.73858
Epoch: 08 [2004/2268 ( 88%)], Train Loss: 0.73582
Epoch: 08 [2044/2268 ( 90%)], Train Loss: 0.73328
Epoch: 08 [2084/2268 ( 92%)], Train Loss: 0.73507
Epoch: 08 [2124/2268 ( 94%)], Train Loss: 0.73493
Epoch: 08 [2164/2268 ( 95%)], Train Loss: 0.73386
Epoch: 08 [2204/2268 ( 97%)], Train Loss: 0.73149
Epoch: 08 [2244/2268 ( 99%)], Train Loss: 0.73410
Epoch: 08 [2268/2268 (100%)], Train Loss: 0.73336
----Validation Results Summary----
Epoch: [8] Valid Loss: 0.63259
Epoch: 09 [ 4/2268 ( 0%)], Train Loss: 0.65229
Epoch: 09 [ 44/2268 ( 2%)], Train Loss: 0.69932
Epoch: 09 [ 84/2268 ( 4%)], Train Loss: 0.66891
Epoch: 09 [ 124/2268 ( 5%)], Train Loss: 0.63769
Epoch: 09 [ 164/2268 ( 7%)], Train Loss: 0.61494
Epoch: 09 [ 204/2268 ( 9%)], Train Loss: 0.65476
Epoch: 09 [ 244/2268 ( 11%)], Train Loss: 0.68624
Epoch: 09 [ 284/2268 ( 13%)], Train Loss: 0.68353
Epoch: 09 [ 324/2268 ( 14%)], Train Loss: 0.67276
Epoch: 09 [ 364/2268 ( 16%)], Train Loss: 0.67240
Epoch: 09 [ 404/2268 ( 18%)], Train Loss: 0.67982
Epoch: 09 [ 444/2268 ( 20%)], Train Loss: 0.67485
Epoch: 09 [ 484/2268 ( 21%)], Train Loss: 0.68309
Epoch: 09 [ 524/2268 ( 23%)], Train Loss: 0.67743
Epoch: 09 [ 564/2268 ( 25%)], Train Loss: 0.67133
Epoch: 09 [ 604/2268 ( 27%)], Train Loss: 0.66746
Epoch: 09 [ 644/2268 ( 28%)], Train Loss: 0.66602
Epoch: 09 [ 684/2268 ( 30%)], Train Loss: 0.66439
Epoch: 09 [ 724/2268 ( 32%)], Train Loss: 0.65516
Epoch: 09 [ 764/2268 ( 34%)], Train Loss: 0.65969
Epoch: 09 [ 804/2268 ( 35%)], Train Loss: 0.65936
Epoch: 09 [ 844/2268 ( 37%)], Train Loss: 0.65999
Epoch: 09 [ 884/2268 ( 39%)], Train Loss: 0.66058
Epoch: 09 [ 924/2268 ( 41%)], Train Loss: 0.65903
Epoch: 09 [ 964/2268 ( 43%)], Train Loss: 0.66478
Epoch: 09 [1004/2268 ( 44%)], Train Loss: 0.66995
Epoch: 09 [1044/2268 ( 46%)], Train Loss: 0.66184
Epoch: 09 [1084/2268 ( 48%)], Train Loss: 0.65755
Epoch: 09 [1124/2268 ( 50%)], Train Loss: 0.66694
Epoch: 09 [1164/2268 ( 51%)], Train Loss: 0.66722
Epoch: 09 [1204/2268 ( 53%)], Train Loss: 0.66794
Epoch: 09 [1244/2268 ( 55%)], Train Loss: 0.66802
Epoch: 09 [1284/2268 ( 57%)], Train Loss: 0.66446
Epoch: 09 [1324/2268 ( 58%)], Train Loss: 0.66499
Epoch: 09 [1364/2268 ( 60%)], Train Loss: 0.66269
Epoch: 09 [1404/2268 ( 62%)], Train Loss: 0.66042
Epoch: 09 [1444/2268 ( 64%)], Train Loss: 0.66217
Epoch: 09 [1484/2268 ( 65%)], Train Loss: 0.66533
Epoch: 09 [1524/2268 ( 67%)], Train Loss: 0.66666
Epoch: 09 [1564/2268 ( 69%)], Train Loss: 0.66603
Epoch: 09 [1604/2268 ( 71%)], Train Loss: 0.66212
Epoch: 09 [1644/2268 ( 72%)], Train Loss: 0.66290
Epoch: 09 [1684/2268 ( 74%)], Train Loss: 0.66560
Epoch: 09 [1724/2268 ( 76%)], Train Loss: 0.66841
Epoch: 09 [1764/2268 ( 78%)], Train Loss: 0.66990
Epoch: 09 [1804/2268 ( 80%)], Train Loss: 0.66665
Epoch: 09 [1844/2268 ( 81%)], Train Loss: 0.66270
Epoch: 09 [1884/2268 ( 83%)], Train Loss: 0.66077
Epoch: 09 [1924/2268 ( 85%)], Train Loss: 0.66624
Epoch: 09 [1964/2268 ( 87%)], Train Loss: 0.67370
Epoch: 09 [2004/2268 ( 88%)], Train Loss: 0.67356
Epoch: 09 [2044/2268 ( 90%)], Train Loss: 0.67474
Epoch: 09 [2084/2268 ( 92%)], Train Loss: 0.67399
Epoch: 09 [2124/2268 ( 94%)], Train Loss: 0.67265
Epoch: 09 [2164/2268 ( 95%)], Train Loss: 0.67291
Epoch: 09 [2204/2268 ( 97%)], Train Loss: 0.67255
Epoch: 09 [2244/2268 ( 99%)], Train Loss: 0.67206
Epoch: 09 [2268/2268 (100%)], Train Loss: 0.67209
----Validation Results Summary----
Epoch: [9] Valid Loss: 0.69677
----SWA Validation Results Summary----
Epoch: [9] Valid Loss: 0.57787
Total Training Time: 1587.333144903183secs, Average Training Time per Epoch: 158.7333144903183secs.
Total Validation Time: 239.26369500160217secs, Average Validation Time per Epoch: 23.926369500160217secs.
Interpreting Transformers with LIT
여기에서는 각 component의 작동 방식에 대한 이해와 함께 LIT를 사용하여 모델 해석을 구현합니다.
How it Works?
LitWidget object constructor는 model 이름을 model object에 mapping하는 dictionary와 dataset 이름을 dataset object에 mapping하는 dictionary를 취합니다. 이들은 LIT에 표시되는 dataset 및 model이 될 것입니다.
또한, 선택적으로 LIT UI를 픽셀 단위로 렌더링할 높이에 대한 height parameter를 받습니다(기본값은 1000 pixels). constructor를 실행하면 LIT 서버가 백그라운드에서 시작되어 모델과 데이터세트를 로드하고 UI를 제공할 수 있습니다.
LitWidget object에서 render method를 호출하여 output cell에서 LIT UI를 렌더링합니다. 원하는 경우, LIT UI를 별도의 cell에서 여러 번 렌더링할 수 있습니다. widget에는 LIT 서버를 종료하는 stop method도 포함되어 있습니다.
Thing to Note LIT는 이 문제로 인해 Kaggle에서 작동하지 않습니다. Kaggle 노트북에서 LIT를 실행하면 kkb-production.jupyter-proxy.kaggle.net이 응답하는 데 너무 오래 걸립니다. Kaggle은 노트북 시작 시간이 크게 느려지기 때문에 이 기능을 비활성화했습니다. 그러나 아래 코드는 플랫폼 독립적이며 local 또는 기타 Google Colab에서 실행됩니다. 여기서는 Colab을 사용했고 snapshot을 공유할 것입니다.
Import Dependencies
Import LIT specific dependencies.
import re
from lit_nlp.api import dataset as lit_dataset
from lit_nlp.api import types as lit_types
from lit_nlp.api import model as lit_model
from lit_nlp.lib import utils
# download snapshots
# ! conda install -y gdown
# !gdown --id 1-RO8zoPGuX4HI1KsvH_Urjg6XxDf-Lq0
# !gdown --id 1-Xcg0lBn6yehLkQnzadrWoCdLg9IGH3-
# !gdown --id 1-UbtAiZsgCgo0SvnNa9uLzO6coPsODv7
# !gdown --id 1-Qm2BYi-STYXfJ6DAK1yb88T7RBMerCh
Implement Dataset
이를 위해 lit_dataset.Dataset class를 상속합니다. 이 class는 우리 모델이 추가적인 전처리, 예측 등을 수행하기 위해 가져올 수 있도록 샘플을 저장합니다.
class CommonLitData(lit_dataset.Dataset):
def __init__(self, df, fold, split='val'):
self._examples = self.load_datapoints(df, fold, split)
def load_datapoints(self, df, fold, split):
if split == 'val':
df = df[df['kfold']==fold].reset_index()
else:
df = df[df['kfold']!=fold].reset_index()
return [{
"excerpt": row["excerpt"],
"label": row["target"],
} for _, row in df.iterrows()]
def spec(self):
return {
'excerpt': lit_types.TextSegment(),
'label': lit_types.RegressionScore(),
}
Implement Model
이것은 우리의 core engine이며 여기에서 lit_model.Model class를 상속합니다. 우리는 predict_minibatch method를 override하고 main transformer로서 pipeline은 모델을 정의하고, 모델 weight을 로드하고, example을 feature로 토큰화하고, 이를 모델에 전달합니다. 그런 다음 cls_embeddings, Attention 및 Gradient의 output을 추가합니다.
class CommonLitModel(lit_model.Model):
compute_grads = False
def __init__(self, args):
self.model, self.config, self.tokenizer = make_model(args, output_attentions=True)
self.model.eval()
def max_minibatch_size(self):
return 8
def predict_minibatch(self, inputs):
encoded_input = self.tokenizer.batch_encode_plus(
[ex["excerpt"].replace("\n", "") for ex in inputs],
add_special_tokens=True,
max_length=256,
padding="max_length",
truncation=True,
return_attention_mask=True
)
encoded_input = {
key : torch.tensor(value, dtype=torch.long) for key, value in encoded_input.items()
}
if torch.cuda.is_available():
self.model.cuda()
for tensor in encoded_input:
encoded_input[tensor] = encoded_input[tensor].cuda()
with torch.set_grad_enabled(self.compute_grads):
outputs = self.model(encoded_input['input_ids'], encoded_input['attention_mask'])
if self.model.config.output_attentions:
logits, hidden_states, output_attentions = outputs[0], outputs[1], outputs[2]
else:
logits, hidden_states = outputs[0], outputs[1]
# encoded_input['attention_mask']: torch.Size([8, 256])
# torch.sum(encoded_input['attention_mask'], dim=1): torch.Size([8])
# hidden_states[-1][:, 0]: torch.Size([8, 768])
# logits: torch.Size([8, 1])
# torch.squeeze(logits, dim=-1): torch.Size([8])
batched_outputs = {
"input_ids": encoded_input["input_ids"],
"ntok": torch.sum(encoded_input["attention_mask"], dim=1),
"cls_emb": hidden_states[-1][:, 0],
"score": torch.squeeze(logits, dim=-1)
}
if self.model.config.output_attentions:
assert len(output_attentions) == self.model.config.num_hidden_layers
for i, layer_attention in enumerate(output_attentions[-2:]):
batched_outputs[f"layer_{i}/attention"] = layer_attention
if self.compute_grads:
scalar_pred_for_gradients = batched_outputs["score"]
batched_outputs["input_emb_grad"] = torch.autograd.grad(
scalar_pred_for_gradients,
hidden_states[0],
grad_outputs=torch.ones_like(scalar_pred_for_gradients)
)[0]
detached_outputs = {k: v.cpu().numpy() for k, v in batched_outputs.items()}
for output in utils.unbatch_preds(detached_outputs):
ntok = output.pop("ntok")
output["tokens"] = self.tokenizer.convert_ids_to_tokens(
output.pop("input_ids")[1:ntok - 1]
)
if self.compute_grads:
output["token_grad_sentence"] = output["input_emb_grad"][:ntok]
if self.model.config.output_attentions:
for key in output:
if not re.match(r"layer_(\d+)/attention", key):
continue
output[key] = output[key][:, :ntok, :ntok].transpose((0, 2, 1))
output[key] = output[key].copy()
yield output
def input_spec(self) -> lit_types.Spec:
return {
"excerpt": lit_types.TextSegment(),
"label": lit_types.RegressionScore()
}
def output_spec(self) -> lit_types.Spec:
ret = {
"tokens": lit_types.Tokens(),
"score": lit_types.RegressionScore(parent="label"),
"cls_emb": lit_types.Embeddings()
}
if self.compute_grads:
ret["token_grad_sentence"] = lit_types.TokenGradients(
align="tokens"
)
if self.model.config.output_attentions:
for i in range(2): # self.model.config.num_hidden_layers
ret[f"layer_{i}/attention"] = lit_types.AttentionHeads(
align_in="tokens", align_out="tokens")
return ret
Run
이제 5-Fold Validation Data 및 모델을 로드하고 이를 notebook.LitWidget에 전달하고 widget.render()를 호출합니다.
그러면 아래와 같은 인터페이스가 열립니다.
def create_model(path):
args = Config()
args.config_name = path
args.model_name_or_path = path
args.tokenizer_name = path
return CommonLitModel(args)
datasets = {
'validation_0': CommonLitData(train, fold=0, split='val'),
'validation_1': CommonLitData(train, fold=1, split='val'),
'validation_2': CommonLitData(train, fold=2, split='val'),
'validation_3': CommonLitData(train, fold=3, split='val'),
'validation_4': CommonLitData(train, fold=4, split='val'),
}
models = {
'model_0': create_model('output/checkpoint-fold-0/'),
'model_1': create_model('output/checkpoint-fold-1/'),
'model_2': create_model('output/checkpoint-fold-2/'),
'model_3': create_model('output/checkpoint-fold-3/'),
'model_4': create_model('output/checkpoint-fold-4/'),
}
from lit_nlp import notebook
widget = notebook.LitWidget(models, datasets, height=800)
# widget.render() -->> uncomment this line to render
Main
Module, group 및 workspace는 LIT의 building block을 형성합니다. module은 특정 task 또는 분석 세트를 수행할 수 있는 개별 window입니다. workspace는 group으로 알려진 module의 조합을 표시하므로 다양한 시각화 및 interpretability method를 나란히 볼 수 있습니다.
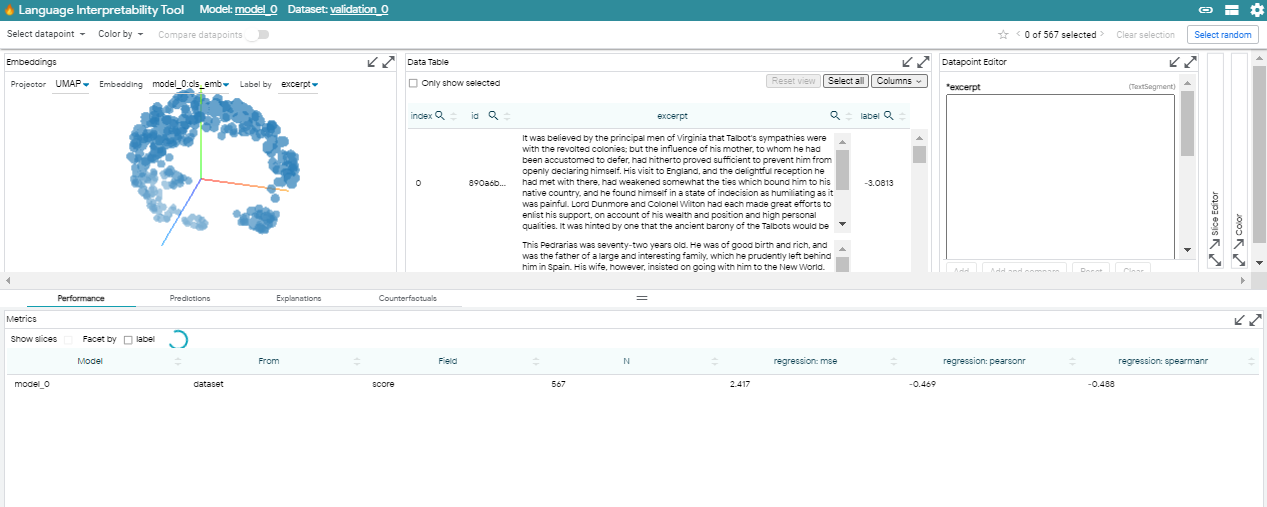
LIT는 인터페이스의 위쪽 절반에 있는 main workspace와 아래쪽에 있는 group-based workspace의 두 가지 작업 영역으로 나뉩니다.
main workspace에는 많은 분석에서 역할을 하는 core module이 포함되어 있습니다. 기본적으로 다음이 포함됩니다:
- Embeddings - 모델에서 UMAO과 TSNE embedding을 explore \
- Data Table - dataset에서 explort, navigate, make selections \
- Datapoint Editor - dataset에서 개별 example을 깊게 탐구 \
- Slice Editor - LIT sesstion을 통해 dataset에서 slices of interest를 만들고 관리
Models and Datasets
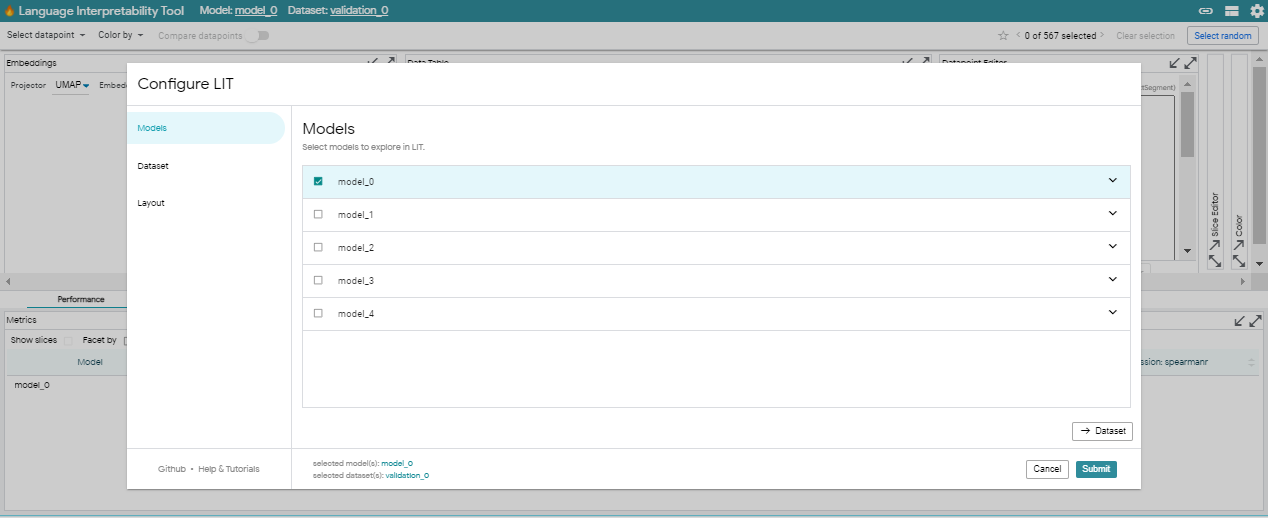
맨 위에는 LIT toolbar이 표시됩니다. 여기에서 로드된 모델을 빠르게 확인하거나 LIT를 구성하거나 세션에 대한 URL을 공유할 수 있습니다. 그 아래에는 모든 LIT에 적용되는 작업을 더 쉽게 수행할 수 있는 toolbar가 있습니다. 여기에서 다음을 수행할 수 있습니다:
- relationship 또는 slice별로 data point를 선택
- 모든 모듈에서 data point에 색상을 지정하는 feature를 선택
- 보고 있는 datapoint를 추적하고, 다음으로 이동하거나, datapoint를 즐겨찾기로 표시하거나, 선택 항목 지우기
- 비교할 여러 모델을 포함하여 active model 및 dataset를 선택
인터페이스 맨 아래의 바닥글에 오류 메시지가 표시됩니다.
Explanations
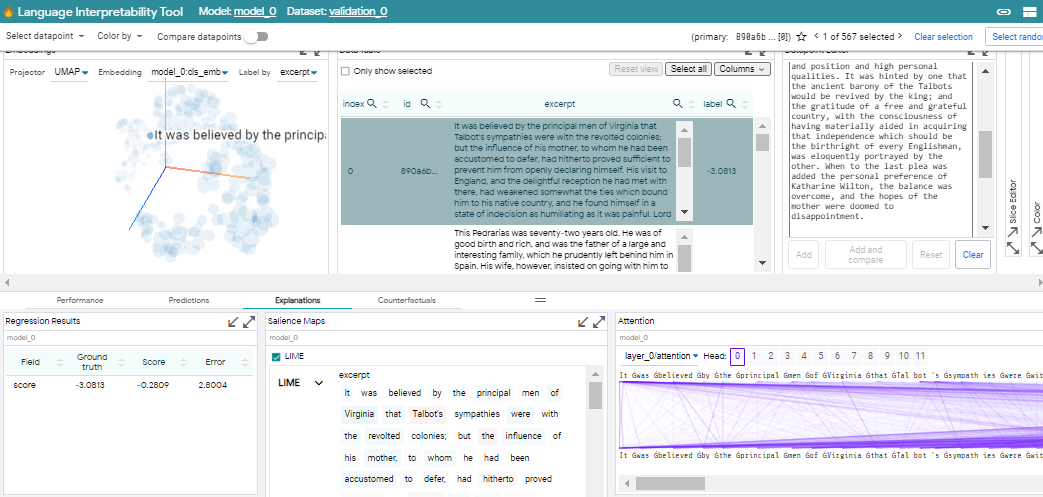
Group-based workspace에서 관련 insight을 제공하는 모듈은 탭 아래 함께 구성됩니다. 기본적으로 LIT는 일반적인 분석 workflow를 기반으로 performance, prediction, explanation 및 counterfactual과 같은 몇 가지 기본 그룹을 제공합니다.
- performance group을 사용하여 전체 dataset 또는 individual slice에서 모델의 성능을 비교
- prediction group의 개별 data point에 대한 모델 결과를 탐색
- explanation group의 다양한 data point에 대한 salience map과 attention을 조사
- Counterfactuals group의 automated generator를 사용하여 data point를 생성하고 즉시 모델을 평가
Extras
이 섹션은 Stochastic Weight Averaging 동안 LR을 해석하는 데 집중합니다. SWA를 사용할 때, learning rate이 어떻게 변경되는지 더 잘 이해하려면 아래 코드를 실행하세요.
model, model_config, optimizer = make_optimizer(args, model)
scheduler = make_scheduler(args, optimizer, 1, 10)
swa_scheduler = SWALR(optimizer, swa_lr=1e-6, anneal_epochs=3, anneal_strategy='cos')
swa_start = 7
for epoch in range(10):
optimizer.step()
if (epoch+1) >= swa_start:
print("starting swa", i)
swa_scheduler.step()
if (epoch+1) < swa_start:
print('using simple scheduler')
scheduler.step()
print(optimizer.param_groups[0]['lr'])
원문
https://www.kaggle.com/code/rhtsingh/swa-apex-amp-interpreting-transformers-in-torch/notebook
댓글남기기